
In veel ontwikkelingslanden zijn nauwelijks betrouwbare data beschikbaar over welvaart of gezondheid van de bevolking. Toch baseert de VN imposante doelstellingen op die schaarse data, en meet er achteraf het succes aan af. Maar hoe zeker weten we of extreme armoede met de helft is afgenomen sinds 1990? Satellietfoto’s en zelflerende algoritmes kunnen nu vrij nauwkeurig armoede op wijk- en dorpsniveau meten.
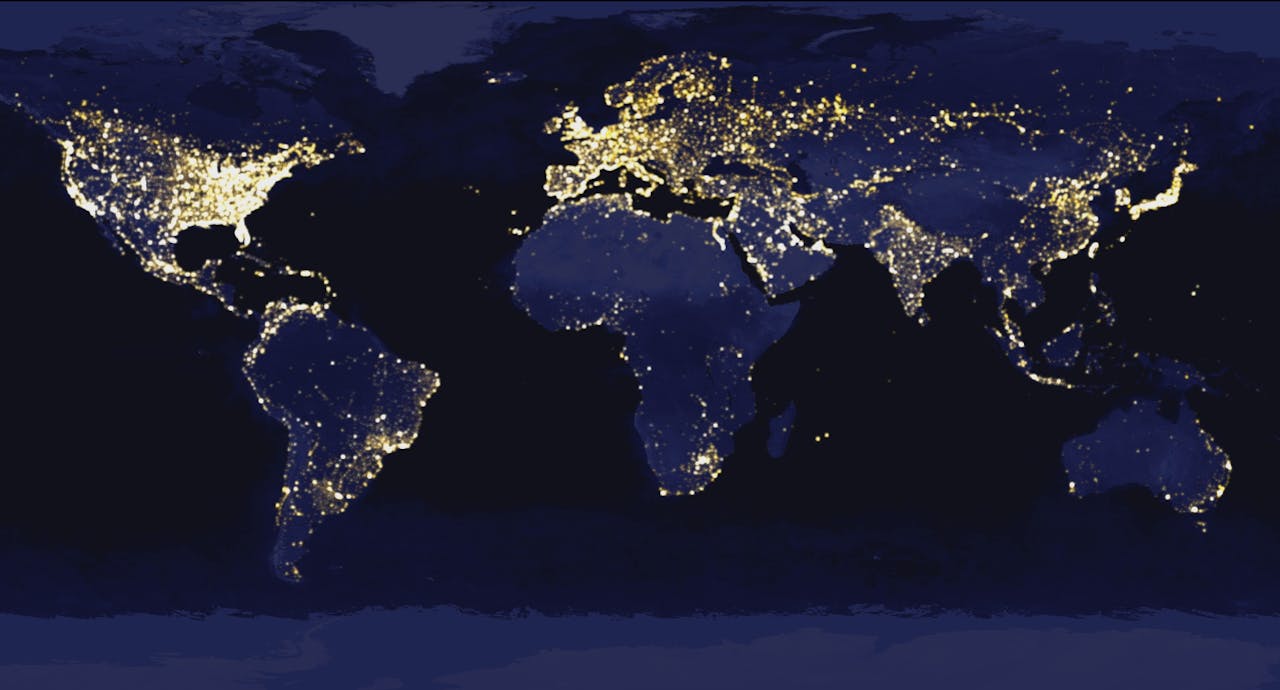
Beeld van de wereld bij nacht, samengesteld uit satellietfoto’s. Hoeveel licht er ‘s nachts brandt, is een redelijk betrouwbare graadmeter voor het algemene welvaartsniveau in een regio. Deze beelden vormen het startpunt voor de methode om extreme armoede te meten.
Arnout Jaspers, via CC 0Officiële cijfers over welvaart, bevolkingsgroei of gezondheid worden nog op zeer traditionele wijze verzameld: enquêteurs reizen het land af, tot in de meest afgelegen dorpjes als het goed is, en laten inwoners vragenlijsten beantwoorden. Het proces is traag, duur en foutgevoelig. En het laat zich raden wat daarvan terechtkomt in gebieden waar oorlog, hongersnood of besmettelijke ziektes heersen. Zelfs in de ontwikkelingslanden waar met enige regelmaat zulke bevolkingsonderzoeken gehouden zijn, moet je maar afwachten of de resultaten eerlijk verwerkt worden, zonder dat de regering nadrukkelijk over de schouders van de rapporteurs meekijkt.
Geen bevolkingsonderzoek
Amerikaanse onderzoekers presenteren deze week in Science een nieuwe meetmethode, gebaseerd op satellietbeelden. Voor de periode 2000 tot 2010 vermelden zij dat van de 59 Afrikaanse landen, er 14 geen enkel bevolkingsonderzoek hebben laten doen, en 25 maar één. Toch rapporteerde de VN in 2015 dat over die periode in heel Afrika onder meer extreme armoede en kindersterfte sterk afnamen.

Van een groot deel van het aardoppervlak zijn overdag genomen hoge-resolutie satellietfoto’s beschikbaar. Als die foto’s op veel plaatsen in allerlei landen gekoppeld waren aan gedetailleerde gegevens over het inkomen van de bewoners aldaar, zou de software rechtstreeks kunnen leren van die foto’s. Maar zulke gekoppelde gegevens zijn te schaars. Daarom gebruikt de methode van Jean en zijn collega’s een extra tussenstap, via nachtelijke satellietbeelden.
Arnout Jaspers, via CC 0De meetmethode van Neal Jean en zijn collega’s van Stanford University gebruikt zelflerende software om publiekelijk beschikbare satellietbeelden automatisch te analyseren. In dit geval is de methode specifiek gebruikt om te schatten hoeveel mensen in extreme armoede leven in vijf Afrikaanse landen, maar de methode zou ook breder toepasbaar kunnen zijn, bijvoorbeeld om de bevolkingsdichtheid of de beschikbaarheid van transport te meten.
Nachtverlichting
Satellietfoto’s worden al gebruikt om de welvaart van een regio te schatten. De hoeveelheid licht die ‘s nachts blijft branden, blijkt een redelijk goede graadmeter voor de welvaart in een regio. In arme buurten is niet of nauwelijks straatverlichting, er zijn geen helverlichte etalages, en in nog armere buurten is helemaal geen elektriciteit. Maar hoewel er meer dan genoeg satellietdata van nachtverlichting beschikbaar zijn, het is een minder goede indicatie voor hoeveel mensen in zo’n gebied in extreme armoede leven (een inkomen van minder dan 1,9 dollar per dag, volgens het VN-criterium).
Aan de onderkant van de maatschappij zit namelijk weinig variatie in de hoeveelheid nachtlicht; simpel gezegd zitten zowel een beetje arm als extreem arm ‘s nachts in het donker. Ook is het op deze manier niet goed mogelijk om een dichtbevolkte, arme wijk te onderscheiden van een dunbevolkte, rijke wijk.
Software trainen
In principe kan zelflerende software ‘getraind’ worden om uit overdag gemaakte hoge-resolutie satellietfoto’s af te leiden hoeveel bewoners daar rijk, arm of iets er tussenin zijn. Hoewel zulke software zelf, op grond van de trainingsdata, beslist welke criteria belangrijk zijn, kun je je voorstellen dat die kijkt naar makkelijk herkenbare aspecten als een zwembad in de achtertuin, meerdere auto’s voor één huis, of anderzijds roestig golfplaat als dak en een chaotisch patroon van smalle steegjes.
Dit zijn fictieve voorbeelden; in feite weet zelfs de maker van de software niet welke kenmerken het systeem gebruikt om armoede te schatten. De software begrijpt ook niet – in de menselijke zin van het woord – wat hij aan het doen is, hij doet gewoon wat het beste blijkt te werken na een check met de echte data.

Satellietbeelden worden eerst op vier manieren gefilterd om bepaalde landschapskenmerken eruit te halen. Dat zijn van links naar rechts: stedelijk gebied, niet-stedelijk gebied, water en wegen.
Boven: originele foto, midden: de ‘activatie-kaart’, met de kenmerken die het desbetreffende filter eruit haalt. Onder: de combinatie van die twee.
Maar dat leerproces lukt alleen als grote aantallen overdag genomen satellietfoto’s beschikbaar zijn van wijken en dorpen waarvoor op de grond gedetailleerde gegevens over de welvaart verzameld zijn, zoals door een enquête ter plekke. Het systeem moet immers zijn aannames over wat in de satellietfoto’s duidt op rijkdom of armoede kunnen checken aan echte data.
Tussenstap
Voor veel ontwikkelingslanden zijn zulke gegevens te schaars om er zelflerende software mee te trainen. Daarom besloot Jeans groep om het systeem via een tussenstap te trainen. Eerst leert het systeem om op grond van satellietfoto’s overdag te ‘voorspellen’ hoeveel licht er ‘s nachts zal branden in een wijk of dorp. Natuurlijk is dit geen echte voorspelling; door deze voorspelling te checken met echte data van de nachtverlichting, krijgt de software telkens feedback waarmee het zijn model kan verbeteren. Het voordeel is, dat ook voor nachtverlichting over de hele wereld hoge-resolutie data beschikbaar zijn. Tenslotte is de software verder getraind met satellietfoto’s overdag van een paar regio’s in vijf Afrikaanse landen waar betrouwbare data over welvaart per wijk wel beschikbaar zijn.
Dan blijkt dat dit model armoede beter voorspelt dan alleen naar de nachtverlichting kijken. Ook blijkt het model nog vrij goed te werken in andere delen van Afrika en zelfs daarbuiten, ondanks dat de cultuur en omstandigheden daar heel anders kunnen zijn.
Zoals de auteurs van het artikel in Science zelf ook opmerken, klinkt dit vreemd: je wilt je software trainen om uit overdag genomen satellietfoto’s de mate van armoede in een wijk af te leiden. Maar een belangrijk deel van die training bestaat uit ‘voorspellen’ hoeveel nachtverlichting er in die wijk zal zijn. Om de eerder genoemde redenen is nachtverlichting niet een heel goede indicator voor armoede. Hoe kan trainen via zo’n tussenstap dan toch een betere schatting van de armoede opleveren dan kijken hoeveel nachtverlichting er echt in die wijk brandt?
Verborgen wijsheid
Strikt genomen moeten de onderzoekers toegeven dat ze het niet weten. Immers, software gebaseerd op zelflerende netwerken beslist zelf welke criteria in de satellietfoto’s relevant zijn. Maar zo’n netwerk heeft niet de mogelijkheid om zijn maker te vertellen hoe het aan zijn wijsheid komt; die zit heel diffuus verweven in de zelflerende software.
Niettemin vermoeden de onderzoekers dat de software de nachtverlichting voorspelt met behulp van meerdere criteria die elk een indicator zijn voor welvaart. Om de hoeveelheid nachtverlichting te voorspellen, moet je die criteria op één hoop gooien, waardoor het goed voorstelbaar is dat nachtverlichting op zich een slechtere voorspeller is van armoede dan wanneer het systeem die criteria afzonderlijk gebruikt om armoede te voorspellen.
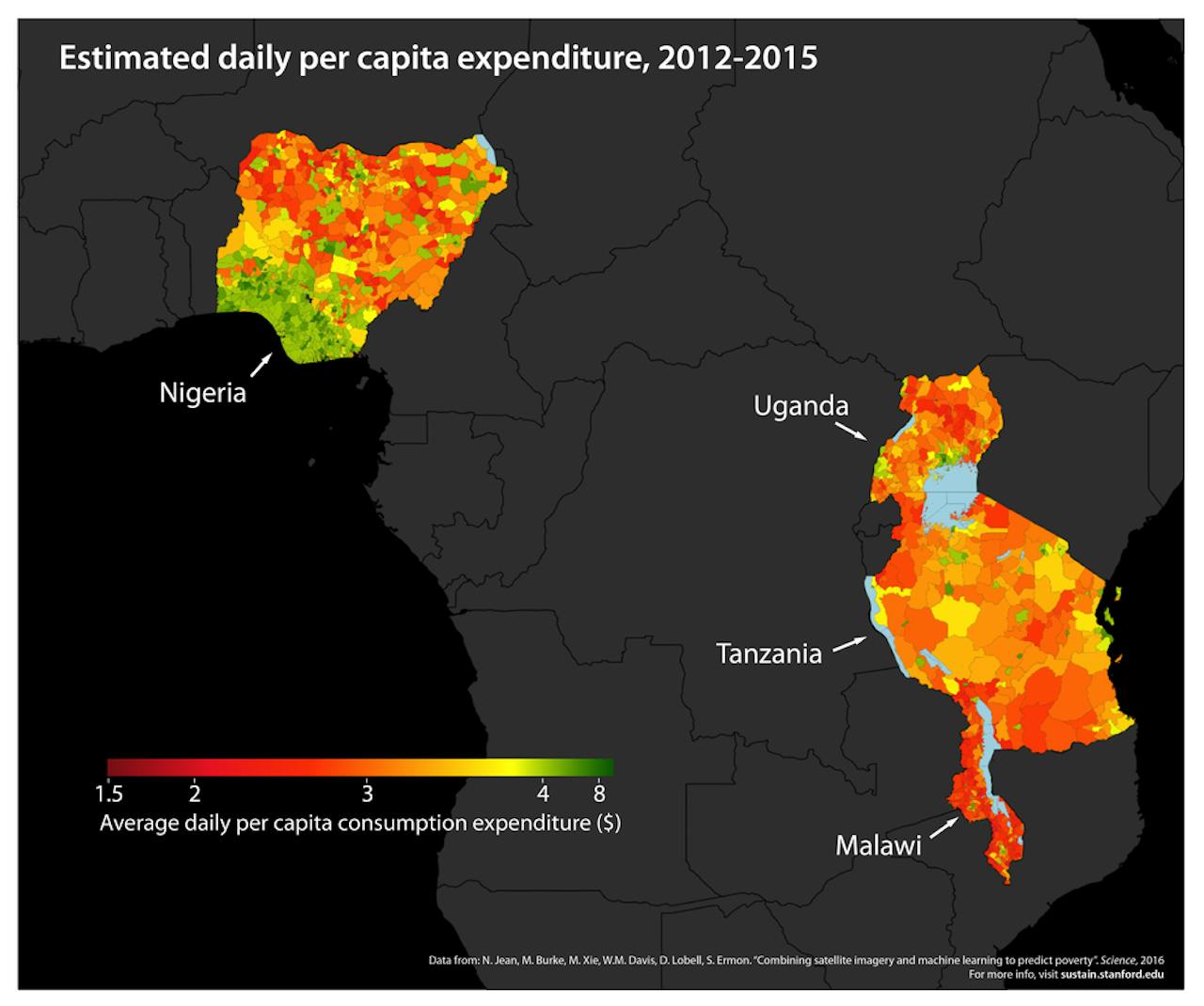
Voorbeeld van een hoge-resolutie armoedekaart, geproduceerd door het zelflerende computermodel van Jeans groep.
Neil Jean e.a., ScienceDatarevolutie
In 2015 kon de VN zowaar eens goed nieuws melden: de millenniumdoelen waren grotendeels gerealiseerd. Extreme armoede en kindersterfte waren wereldwijd sterk afgenomen, veel meer meisjes gingen naar school en veel meer mensen hadden toegang tot gezondheidszorg.
Maar de kritiek op de betrouwbaarheid van de cijfers was niet mals. Mocht je daar wel zulke conclusies op baseren? De VN erkent dat het gebrek aan betrouwbare data een groot probleem is. Daarom is voor het volgende mondiale ontwikkelingsprogramma, de Sustainable Developtment Goals, een ‘datarevolutie’ nodig, zegt de VN.
Hordes enquêteurs daarvoor de wereld in sturen is onhaalbaar. De data zullen moeten komen van satellieten, maar ook van mobiele telefoonnetwerken, of zelfs Facebook en Twitter. Zelflerende netwerken die dit type massaal beschikbare data intelligent kunnen analyseren, zullen daar een grote rol in spelen. En misschien weten we dan in 2030 écht of de Sustainable Developtment Goals gerealiseerd zijn.
'%20fill='%23000'%3e%3cpath%20d='M1.28%2022.5c-.505%200-.826-.018-.862-.018a.44.44%200%2001-.238-.792l2.425-1.778A8.266%208.266%200%2001.326%2014.22c0-4.559%203.71-8.268%208.268-8.268a8.269%208.269%200%20018.087%206.556c.119.559.176%201.135.176%201.716%200%204.554-3.705%208.263-8.263%208.263-.907%200-1.804-.15-2.667-.44-1.782.392-3.608.458-4.646.458V22.5zM8.595%206.83c-4.075%200-7.388%203.313-7.388%207.388%200%202.055.867%204.03%202.376%205.416.097.088.15.216.14.348a.448.448%200%2001-.18.33L1.774%2021.61c1.06-.022%202.609-.119%204.083-.458a.468.468%200%2001.246.013%207.414%207.414%200%20002.49.432c4.07%200%207.384-3.314%207.384-7.384a7.385%207.385%200%2000-6.41-7.322%207.849%207.849%200%2000-.973-.06z'/%3e%3cpath%20d='M20.944%2013.102c-.775%200-2.139-.049-3.48-.34-.37.124-.758.216-1.154.27a.44.44%200%2001-.492-.344%207.395%207.395%200%2000-6.253-5.795.44.44%200%2001-.383-.462A6.287%206.287%200%200115.462.5c3.334%200%206.296%202.825%206.296%206.296%200%201.571-.594%203.09-1.65%204.242l1.711%201.254a.439.439%200%2001-.238.792c-.03%200-.263.013-.637.013v.005zm-3.507-1.237c.03%200%20.066%200%20.097.009.941.216%201.918.3%202.675.33l-1.034-.761a.448.448%200%2001-.18-.33.431.431%200%2001.14-.348%205.412%205.412%200%20001.743-3.969A5.421%205.421%200%200015.46%201.38a5.407%205.407%200%2000-5.363%204.708%208.275%208.275%200%20016.48%206.002c.243-.053.48-.12.71-.198a.428.428%200%2001.149-.027z'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='prefix__clip0_1886_150885'%3e%3cpath%20fill='%23fff'%20transform='translate(0%20.5)'%20d='M0%200h22v22H0z'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e) Reageer
Reageer