

Het gebeurt regelmatig: iemand krijgt een twitterban opgelegd omdat hij bijvoorbeeld over corona of vaccinaties twittert. Staan de filters van Facebook en Twitter niet te streng afgesteld? We spraken met taaltechnoloog Antal van den Bosch.
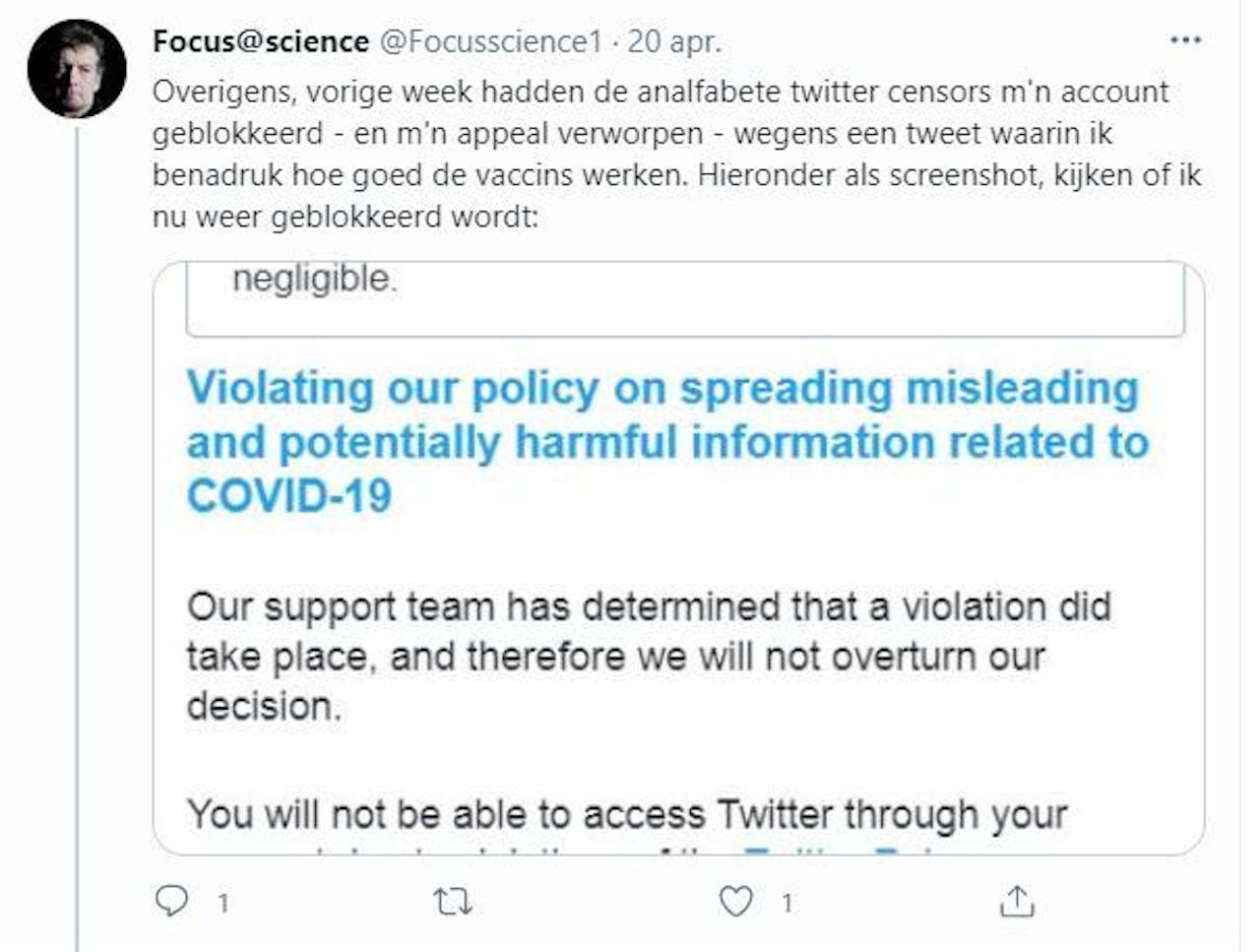
Sociale media als Twitter en Facebook gebruiken algoritmes om verspreiders van nepnieuws en haatdragende berichten op te merken. Maar ook goed bedoelde tweets worden door die algoritmes nogal eens aangemerkt als ongewenst. Zo gebeurt het de laatste tijd regelmatig dat mensen tijdelijk een ‘twitterban’ opgelegd krijgen omdat ze bijvoorbeeld schrijven over corona of vaccinaties en hun tweet net die woorden bevat die het algoritme gebruikt om nepnieuws op te sporen. Dat gebeurde onder andere onze collega-journalist Arnout Jaspers die in een tweet benadrukte hoe goed vaccins werken.
Zelfs de bestuursvoorzitter van het OLVG in Amsterdam werd van LinkedIn verwijderd toen hij aandacht vroeg voor de neveneffecten van de coronamaatregelen. Ook kan het algoritme de fout ingaan door een taaldwaling. Zo kreeg de Vlaamse taalkundige Miet Ooms een twitterban opgelegd na het versturen van de tweet ‘Topinfluencer, die Bernie’. Het twitterfilter zag de tweet ten onrechte aan voor een Engelstalig bericht waarin iemand de politicus Bernie Sanders dood wenste.
Waarom gaat het algoritme nog zo vaak de fout in en kan dat in de toekomst anders? NEMO Kennislink sprak erover met taaltechnoloog Antal van den Bosch. Hij is hoogleraar Taal en Kunstmatige intelligentie aan de UvA en directeur van het Meertens Instituut.
Waarom gaan de algoritmes zo vaak de mist in?
“Welke filters bedrijven als Facebook en Twitter precies gebruiken weet niemand. Maar in het algemeen is het zo dat ze een combinatie hanteren van menselijke moderatie en automatische filters. Omdat het om zulke gigantische hoeveelheden data gaat, staat er in eerste instantie een hele batterij aan automatische filters klaar, die als het ware vlaggetjes plaatst bij ongewenste tweets. Wat ongewenst is, is terug te vinden in de richtlijnen van zo’n bedrijf. Voorbeelden zijn haat zaaien, bedreigen, desinformatie en misinformatie. De taak van de menselijke moderatoren is om steekproefsgewijs te controleren of de vlaggetjes terecht zijn.”

Meestal scoren automatische filters die sociale media gebruiken tussen de 75 en 85 procent.
Pixabay CC0“Die automatische filters zijn computerprogramma’s die min of meer werken zoals een spamfilter twintig jaar geleden al werkte. Naïef zou je zeggen: zo’n algoritme heeft het goed of heeft het fout. Maar eigenlijk – en dat is vaak een eyeopener – zijn er vier uitkomsten mogelijk, waarvan er twee goed zijn en twee fout. Het gaat goed bij de berichten die volgens het algoritme en ook volgens de menselijke maat aanstootgevend zijn. Hetzelfde geldt voor berichten die het algoritme terecht goedkeurt. Maar het gaat fout bij vals positieven en vals negatieven. In het eerste geval zegt het algoritme dat het bericht niet op de site hoort terwijl er in feite niks mis mee is; in het tweede geval zegt het algoritme dat er niks aan de hand is, terwijl het wel degelijk aanstootgevend is.”
“Het probleem is dat er geen algoritme bestaat dat het honderd procent goed doet. Meestal scoren ze ergens tussen de 75 en 85 procent. Maar dat getal zegt nog niets over de verdeling van de vals positieven en vals negatieven. Die verdeling kun je zien als een touwtrekwedstrijd. Trek je aan de ene kant, om het aantal vals positieven terug te dringen, dan krijg je een heleboel vals negatieven. Je zult dus voortdurend moeten testen hoe goed je algoritme werkt op beide typen fouten.”
Wat is dan de beste verdeling tussen de twee typen fouten?
“Dat hangt er vanaf wat je wilt. Als je bijvoorbeeld heel veel menselijke moderatoren in dienst hebt, dan hoeft het algoritme niet zo precies te zijn. De menselijke moderatoren keuren dan de onterecht afgekeurde berichten alsnog goed. Je kunt je dan meer vals positieven veroorloven. Maar als het algoritme volledig automatisch werkt, dan wil je wél dat deze heel precies is.”
Waarschijnlijk hebben Twitter en Facebook veel menselijke moderatoren in dienst?
“Absoluut. Maar uiteindelijk is het nooit genoeg. Dus ook daar zullen ze weer een soort evenwicht in moeten vinden. Je moet eerst bepalen wat de moderatieteams aan kunnen. Het controleren van die ‘vlaggetjes’ gaat eigenlijk altijd steekproefsgewijs: je kunt niet alles controleren. Maar moderatie is bijvoorbeeld ook taal- en cultuurafhankelijk. Je zult in Nederland echt mensen moeten hebben die dat voor Nederlandstalige berichten doen. En dan moet er ook altijd een deel van het team zijn dat nazorg levert aan mensen die bezwaar indienen omdat ze geblokkeerd zijn. Ik denk dat deze bedrijven veel tijd steken in die nazorg. Daarmee houd je toch je klantrelaties goed.”
Het lijkt er dus op dat de huidige algoritmes veel vals positieven opleveren: berichten die ten onrechte als aanstootgevend worden aangemerkt. Wat gaat hier taaltechnologisch gezien fout?
“Het is heel moeilijk voor algoritmes om alle nuances van een bewering te detecteren. Dit gebeurt bijvoorbeeld als je iets quote waar je het niet mee eens bent: je gebruikt dan immers wel woorden die in de verboden hoek zitten, naast je eigen inbreng als ‘ik snap niet waarom mensen nog altijd beweren dat…’. Het onterecht wegfilteren van zulke nuance gaat uiteindelijk ten koste van het debat. Elk gezond debat heeft baat bij common ground, gedeelde kennis, anders kan je elkaar niet begrijpen. In het zwartepietdebat is ‘zwarte piet’ een beladen term, maar als we ons in geheimtaal moeten gaan hullen dan is de discussie steeds verder weg. Tegelijkertijd hebben we de filters toch wel nodig, want zonder een vorm van moderatie kunnen discussies totaal ontsporen.”
“Algoritmes hebben moeite met het duiden van wat het betekent als een bewering begint met ‘ik vind’ of ‘ik snap niet waarom’ en woorden die voorzichtigheid uitdrukken zoals ‘misschien’. En dat zijn juist heel belangrijke aanwijzingen dat er iets meer aan de hand is dan dat iemand een scheldpartij aan het opzetten is. De meest geavanceerde algoritmes proberen dat nu wel mee te nemen. Ze kijken sowieso naar woordgroepen en woordcombinaties in plaats van naar individuele woorden, en dus ook steeds vaker naar de relatieve positie van die woorden.”
“Een andere moeilijkheid is de factor tijd. Door de tijd heen komen nieuwe onderwerpen op, of verandert de hoeveelheid aandacht die een bepaald onderwerp krijgt. Je moet die algoritmes dus vaak bijtrainen, want er kan zomaar een beweging ontstaan, een hashtag, een persoon die van de ene op de andere dag beroemd wordt zoals George Floyd. Wat ook nogal eens misgaat is de taalidentificatie, dus in welke taal een bericht is geschreven: hoe korter de boodschap, hoe vaker het misgaat. Neem de woorden in die tweet van Miet Ooms, ‘die Bernie’: op basis van een eigennnaam kun je nog niet beslissen met welke taal je te maken hebt, en het woordje ‘die’ komt in meerdere talen voor met een andere betekenis. Hier heeft het algoritme het Nederlands aangezien voor Engels.”
Kunnen de automatische algoritmes bij het overwinnen van deze problemen naar honderd procent foutloos modereren?
“Dat denk ik niet. Als je dit door verschillende menselijke moderatoren laat doen dan krijg je scores die ook geen honderd procent zijn, omdat er verschil van mening is. En het algoritme is getraind op menselijke data. Het is misschien wel zo dat als je data laat labelen door meerdere mensen en daar weer een discussie overheen laat gaan, die data weer aanbiedt als trainingsmateriaal, dan heb je wel materiaal dat misschien een soort collectieve intelligentie representeert. Misschien kom je op die manier wel ooit uit bij een heel intelligent algoritme.”
'%20fill='%23000'%3e%3cpath%20d='M1.28%2022.5c-.505%200-.826-.018-.862-.018a.44.44%200%2001-.238-.792l2.425-1.778A8.266%208.266%200%2001.326%2014.22c0-4.559%203.71-8.268%208.268-8.268a8.269%208.269%200%20018.087%206.556c.119.559.176%201.135.176%201.716%200%204.554-3.705%208.263-8.263%208.263-.907%200-1.804-.15-2.667-.44-1.782.392-3.608.458-4.646.458V22.5zM8.595%206.83c-4.075%200-7.388%203.313-7.388%207.388%200%202.055.867%204.03%202.376%205.416.097.088.15.216.14.348a.448.448%200%2001-.18.33L1.774%2021.61c1.06-.022%202.609-.119%204.083-.458a.468.468%200%2001.246.013%207.414%207.414%200%20002.49.432c4.07%200%207.384-3.314%207.384-7.384a7.385%207.385%200%2000-6.41-7.322%207.849%207.849%200%2000-.973-.06z'/%3e%3cpath%20d='M20.944%2013.102c-.775%200-2.139-.049-3.48-.34-.37.124-.758.216-1.154.27a.44.44%200%2001-.492-.344%207.395%207.395%200%2000-6.253-5.795.44.44%200%2001-.383-.462A6.287%206.287%200%200115.462.5c3.334%200%206.296%202.825%206.296%206.296%200%201.571-.594%203.09-1.65%204.242l1.711%201.254a.439.439%200%2001-.238.792c-.03%200-.263.013-.637.013v.005zm-3.507-1.237c.03%200%20.066%200%20.097.009.941.216%201.918.3%202.675.33l-1.034-.761a.448.448%200%2001-.18-.33.431.431%200%2001.14-.348%205.412%205.412%200%20001.743-3.969A5.421%205.421%200%200015.46%201.38a5.407%205.407%200%2000-5.363%204.708%208.275%208.275%200%20016.48%206.002c.243-.053.48-.12.71-.198a.428.428%200%2001.149-.027z'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='prefix__clip0_1886_150885'%3e%3cpath%20fill='%23fff'%20transform='translate(0%20.5)'%20d='M0%200h22v22H0z'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e) Reageer
Reageer