

Voor klimaat- en milieu-beleid is het van groot belang te weten hoe belastend allerlei producten voor het milieu zijn, de zogeheten voetafdruk. In zijn promotieonderzoek snoeide Zoran Steinmann de wildgroei aan indicatoren waarmee deze wordt berekend drastisch terug. Vier indicatoren bepalen de voetafdruk bijna net zo goed als honderd.
Wat is effectiever? Stoppen met vlees eten, of dubbel glas aanbrengen? Wat belast het milieu meer: een kind krijgen of drie keer per jaar op vliegvakantie? Als je echt wilt uitrekenen wat de milieu-impact is van allerlei producten en activiteiten, moet je een life cycle analysis (LCA) doen. In zo’n LCA probeer je de totale milieukosten in kaart te brengen.
Neem bijvoorbeeld een hybride elektrische auto. Deze kan op benzine of elektriciteit rijden; de kilometers op elektriciteit veroorzaken geen directe CO2-uitstoot, maar wel degelijk indirect, via de elektriciteitsproductie. Dan is er nog de productie van de auto, de banden, de accu, en de hele infrastructuur van wegen en dergelijke die je in rekening moet brengen. Het directe verbruik en de bijbehorende CO2-uitstoot per passagier of per kilometer is vrij simpel te berekenen. Maar wat is de milieu-impact van het totale systeem?
Daarbij moet je niet alleen naar CO2-uitstoot kijken, maar ook naar het waterverbruik, de invloed op de ozonlaag, het landgebruik en de invloed daarvan op de biodiversiteit, en ga zo maar door. In theorie is het aantal vertakkingen vrijwel oneindig, maar in de praktijk houden onderzoekers bij een LCA natuurlijk ergens op met effecten in rekening te brengen, onder de aanname dat nog verder kijken weinig meer uitmaakt. Maar bij verschillende LCA’s worden in totaal meer dan honderd indicatoren gebruikt om de voetafdruk te bepalen.

Bij een Life Cycle Analysis moeten alle milieu-effecten van een product worden meegewogen, van productie tot afvalverwerking.
Arnout Jaspers voor NEMO KennislinkZoran Steinmann, milieukundige aan de Nijmeegse Radboud Universteit, heeft als onderdeel van zijn promotie-onderzoek drastisch het mes gezet in deze wildgroei. Met een beproefde wiskundige techniek, Principal Component Analysis (PCA), kon hij aantonen dat je in plaats van de 135 indicatoren die werden gebruikt voor bijna duizend producten in de Ecoinvent-database, eigenlijk net zo goed maar 4 indicatoren kunt gebruiken. Dit ondanks de enorme diversiteit in die producten, van cementblokken tot LCD-schermen. Ecoinvent is een Zwitserse non-profit organisatie die over een scala aan producten en processen milieugegevens verzamelt.
Steinmann: “Deze grote afname komt onder andere omdat de producten in mijn studie allemaal op basis van 1 kilogram worden vergeleken; een kilogram goud heeft altijd een grotere impact dan een kilogram graankorrels, ongeacht naar welke indicator je kijkt.” Als een kilo goud op alle fronten een veel grotere voetafdruk heeft dan een kilo graan, is er alleen al om die reden een vrij sterke samenhang tussen alle indicatoren.
Dat je met veel minder indicatoren toe kunt, kwam dus niet onverwacht. Interessanter is, dat veel indicatoren ook samenhangen door de manier waarop productieprocessen in elkaar zitten. Steinmann: “Bepaalde processen in de productieketens van producten (bijvoorbeeld elektriciteitsopwekking met kolen) zorgen voor impacts voor verschillende categorieën. Verbranding van kolen veroorzaakt bijvoorbeeld gelijktijdig klimaatverandering, uitstoot van fijnstof en nog wat andere impacts. Daardoor vertonen deze indicatoren, die voor heel verschillende milieu-problemen ontwikkeld zijn, toch veel samenhang.”
Steinmanns afdeling Milieukunde van de Radboud Universiteit werkt samen met Unilever, een voor sommigen wellicht verrassende partner. Unilever maakt een groot aantal consumentenproducten, en wil zelf ook inzicht krijgen in de voetafdruk daarvan, om de eigen productieprocessen te verbeteren.
Complexe datasets
PCA is een manier om zo efficiënt mogelijk complexe datasets te karakteriseren. Het principe is het makkelijkst te begrijpen als er maar twee indicatoren voor de voetafdruk zijn, zeg CO2-uitstoot en waterverbruik. Voor elk product (1 kilo goud, 1 kilo graan, enz.) hebben die indicatoren een bepaalde waarde, zodat je elk product kunt weergeven als een punt in een tweedimensionale grafiek met als assen: CO2-uitstoot en waterverbruik. De totale voetafdruk van elk product wordt dan gegeven door een vaste formule waarin die indicatoren voorkomen (fictief voorbeeld: de som van de CO2-uitstoot in kilo’s en het waterverbruik in kubieke meters).
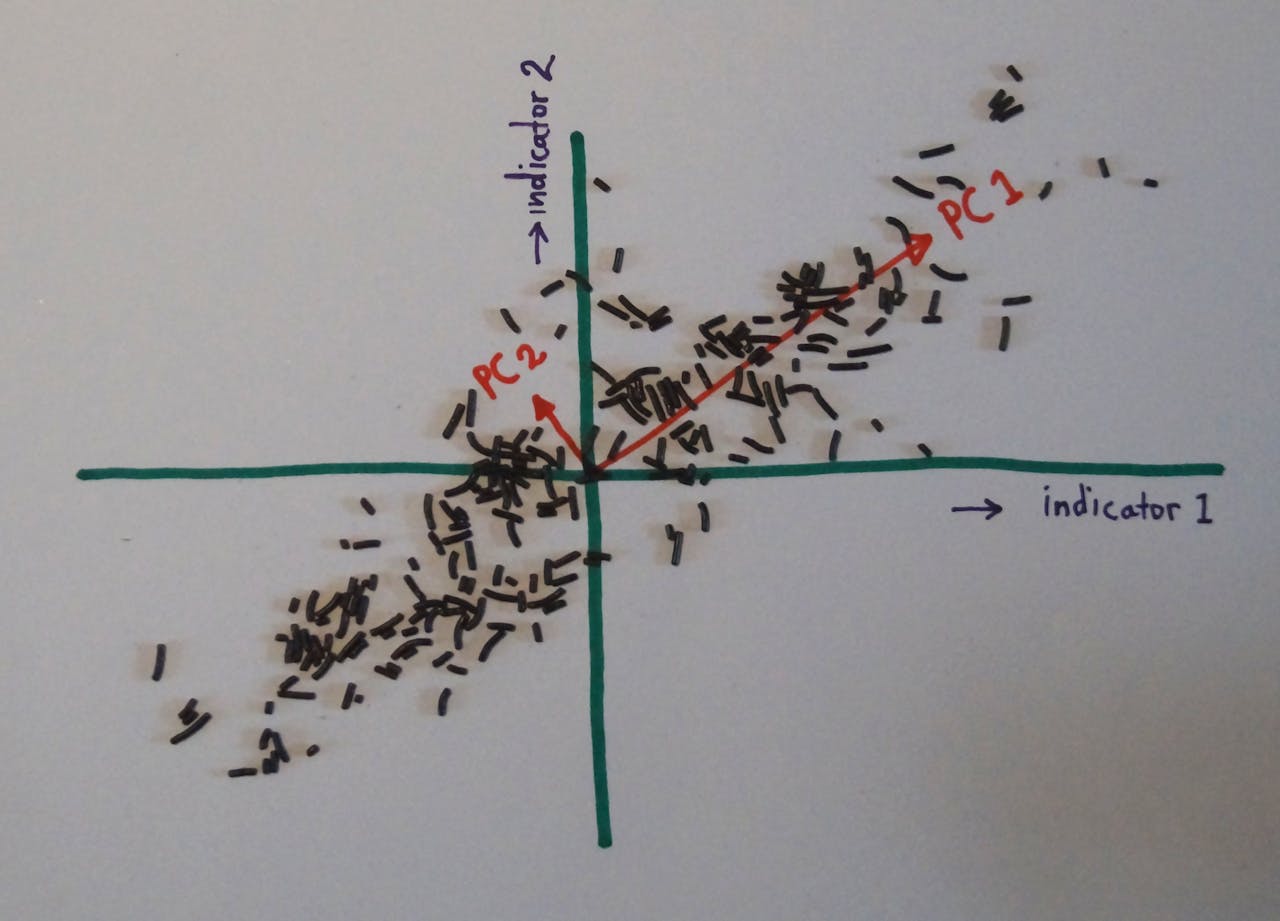
Een dataset kun je zien als een puntenwolk in een abstracte ruimte (hier van slechts twee dimensies, maar veel meer kan ook). Met PCA geef je een efficiëntere beschrijving van zo’n dataset door het coördinatenstelsel te draaien.
Arnout Jaspers voor NEMO KennislinkAls je veel producten hebt, ziet die grafiek er uit als een puntenwolk (zie afbeelding hierboven). Op grond van de vorm van die puntenwolk bepaalt PCA nu nieuwe assen in die grafiek, PC1 en PC2. Per definitie ligt PC1 langs de grootste breedte van de wolk, PC2 staat daar loodrecht op.
PC1 is een geoptimaliseerde indicator, die in zijn eentje al voor het grootste deel de voetafdruk bepaalt. Immers, als je voor een product de waarde van PC1 weet, kan de voetafdruk daar nog maar weinig van afwijken, omdat de puntenwolk in de richting van PC2 heel wat smaller is. Principal component analysis levert niet altijd iets op; als de puntenwolk vormloos is, zijn PC1 en PC2 ongeveer even groot en schiet je er weinig mee op (zie onderstaande afbeelding).
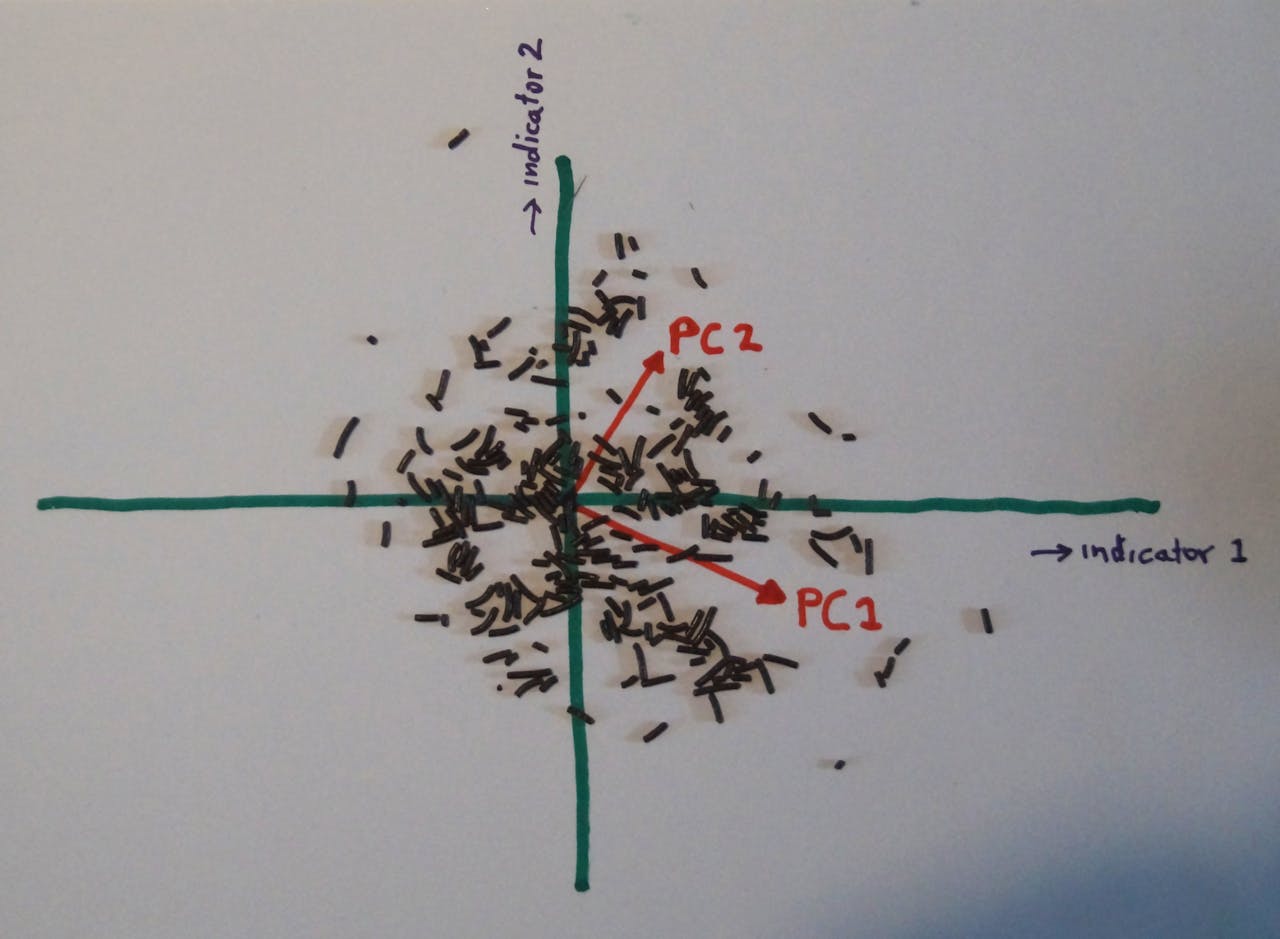
Als een dataset uit random data bestaat, of als alle indicatoren volledig onafhankelijk van elkaar zijn, levert een PCA geen efficiëntere beschrijving op. Maar in echte datasets zit bijna altijd enige structuur die zich met PCA eruit laat halen.
Arnout Jaspers voor NEMO KennislinkPCA kan toegepast worden met een willekeurig aantal indicatoren, in dit geval dus 135. Je kijkt dan naar een abstracte puntenwolk in een ruimte van 135 dimensies. Een computeralgoritme zoekt in die ruimte naar de richting waarin de puntenwolk het breedst is (PC1), vervolgens naar de op één na breedste richting loodrecht daarop (PC2), dan de op twee na breedste richting (PC3), enzovoort.
Puntenwolk
Echte datasets leveren meestal een puntenwolk met een duidelijke structuur op, met breedtes die in een paar richtingen duidelijk groter zijn dan de rest. Daarom kan je met PCA vaak een groot deel van de variantie in de dataset verklaren door slechts een handjevol PC’s, al zijn er formeel altijd evenveel PC’s als indicatoren, hier dus 135.
Bij PCA is het altijd een discussiepunt hoeveel PC’s je ‘meeneemt’ in je analyse, aangezien ze snel kleiner worden. Dit betekent: opeenvolgende PC’s hebben steeds minder verklarende waarde voor de voetafdruk. Steinmann: “Ik stop met PC’s ‘meenemen’ als ze niet méér variantie kunnen verklaren dan je op basis van een random dataset zou verwachten. De achterliggende gedachte is: dit is alle structuur die je uit de data kunt halen, de rest beschouwen we als ruis.”
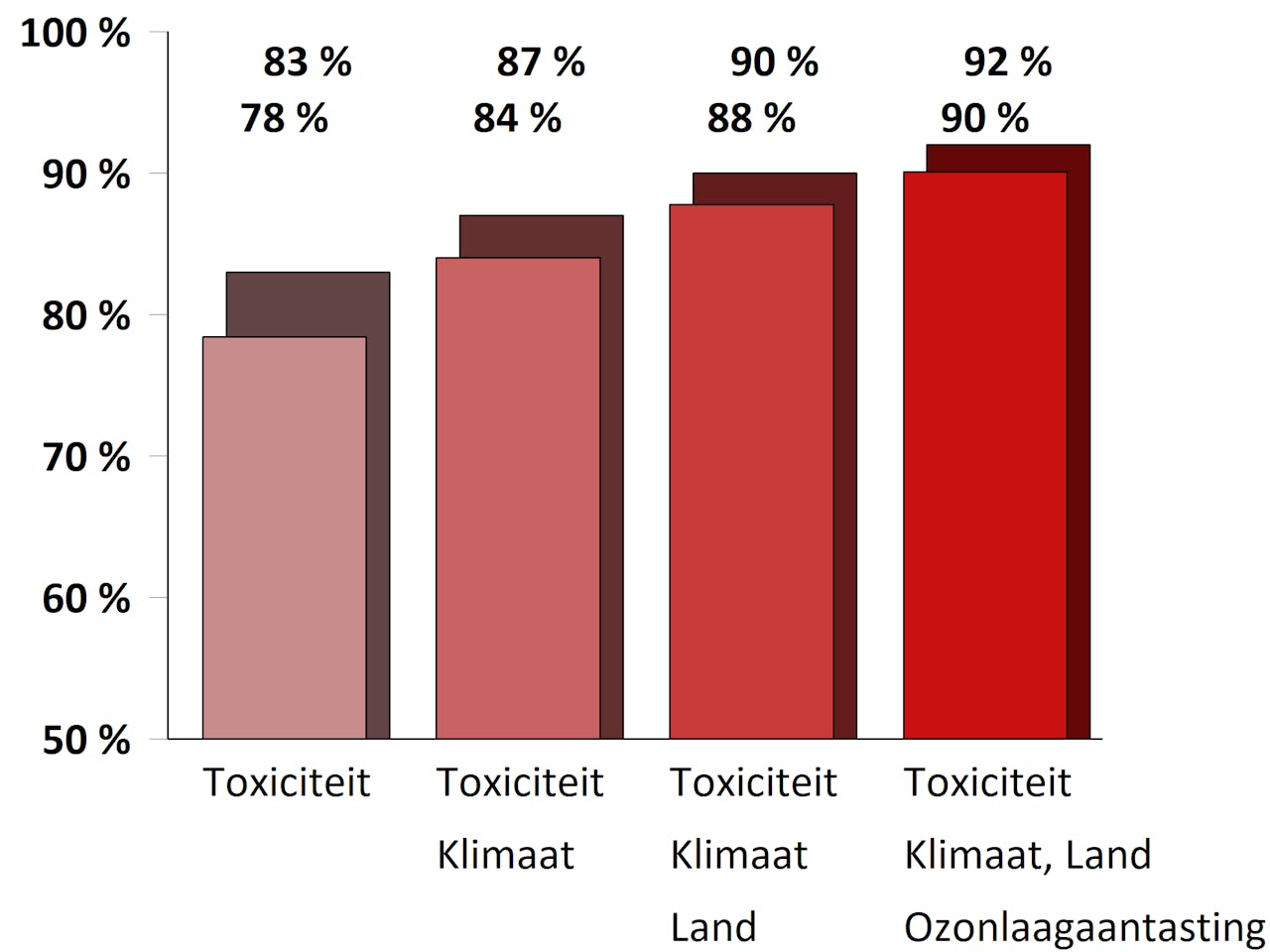
Resultaten van een Principal Component Analyse van 135 indicatoren voor bijna duizend producten. De balkjes op de achtergrond geven aan in hoeverre principal component 1,2,3 en 4 (cumulatief) voorspellend zijn voor de voetafdruk van deze producten.
Vervolgens zijn indicatoren (de balkjes op de voorgrond) gezocht die individueel vrijwel net zo voorspellend zijn als de principal components. Zelfs met één indicator is al bijna tachtig procent van de variantie in de voetafdruk van deze producten te voorspellen. De tweede, derde en vierde indicator voegen steeds minder voorspellende waarde toe.
Dan blijkt, dat slechts vier PC’s voor deze dataset al genoeg zijn, en dat die 92 procent van de variantie verklaren. Met dat resultaat in het achterhoofd, ging Steinmann vervolgens in de oorspronkelijke 135 indicatoren op zoek naar een klein setje dat bijna net zo voorspellend was voor de voetafdruk als de vier PC’s. Dat lukte: de indicatoren ‘toxiciteit’, ‘klimaatverandering’, ‘landgebruik’ en ‘aantasting ozonlaag’ verklaren samen ook al 90 procent van de variantie. Op deze manier kan dus veel sneller de voetafdruk van producten bepaald worden. Ook zijn voetafdrukken die met verschillende sets indicatoren bepaald werden, nu beter vergelijkbaar.
'%20fill='%23000'%3e%3cpath%20d='M1.28%2022.5c-.505%200-.826-.018-.862-.018a.44.44%200%2001-.238-.792l2.425-1.778A8.266%208.266%200%2001.326%2014.22c0-4.559%203.71-8.268%208.268-8.268a8.269%208.269%200%20018.087%206.556c.119.559.176%201.135.176%201.716%200%204.554-3.705%208.263-8.263%208.263-.907%200-1.804-.15-2.667-.44-1.782.392-3.608.458-4.646.458V22.5zM8.595%206.83c-4.075%200-7.388%203.313-7.388%207.388%200%202.055.867%204.03%202.376%205.416.097.088.15.216.14.348a.448.448%200%2001-.18.33L1.774%2021.61c1.06-.022%202.609-.119%204.083-.458a.468.468%200%2001.246.013%207.414%207.414%200%20002.49.432c4.07%200%207.384-3.314%207.384-7.384a7.385%207.385%200%2000-6.41-7.322%207.849%207.849%200%2000-.973-.06z'/%3e%3cpath%20d='M20.944%2013.102c-.775%200-2.139-.049-3.48-.34-.37.124-.758.216-1.154.27a.44.44%200%2001-.492-.344%207.395%207.395%200%2000-6.253-5.795.44.44%200%2001-.383-.462A6.287%206.287%200%200115.462.5c3.334%200%206.296%202.825%206.296%206.296%200%201.571-.594%203.09-1.65%204.242l1.711%201.254a.439.439%200%2001-.238.792c-.03%200-.263.013-.637.013v.005zm-3.507-1.237c.03%200%20.066%200%20.097.009.941.216%201.918.3%202.675.33l-1.034-.761a.448.448%200%2001-.18-.33.431.431%200%2001.14-.348%205.412%205.412%200%20001.743-3.969A5.421%205.421%200%200015.46%201.38a5.407%205.407%200%2000-5.363%204.708%208.275%208.275%200%20016.48%206.002c.243-.053.48-.12.71-.198a.428.428%200%2001.149-.027z'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='prefix__clip0_1886_150885'%3e%3cpath%20fill='%23fff'%20transform='translate(0%20.5)'%20d='M0%200h22v22H0z'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e) Reageer
Reageer