
Welke talen worden het meest met elkaar verward? Wetenschappers kunnen hierover voorspellingen doen op basis van taalkundige theorieën over taalgelijkenis. Maar in de praktijk spelen andere factoren een grotere rol, zo blijkt uit de antwoorden van spelers van het online spel The Great Language Game.
Spelers van The Great Language Game luisteren naar een audiofragment en kiezen vervolgens uit een aantal mogelijkheden de taal de ze hebben gehoord. Sinds begin 2014 speelden wereldwijd bijna een miljoen mensen het online spel met vierhonderd opnames uit 78 verschillende talen. Dit leverde in totaal ruim vijftien miljoen antwoorden op. Met deze schat aan data kon een team van Australische en Nederlandse taalwetenschappers kijken welke factoren een rol spelen bij het herkennen van talen. Welke talen worden het best herkend en welke juist het meest door elkaar gehaald?
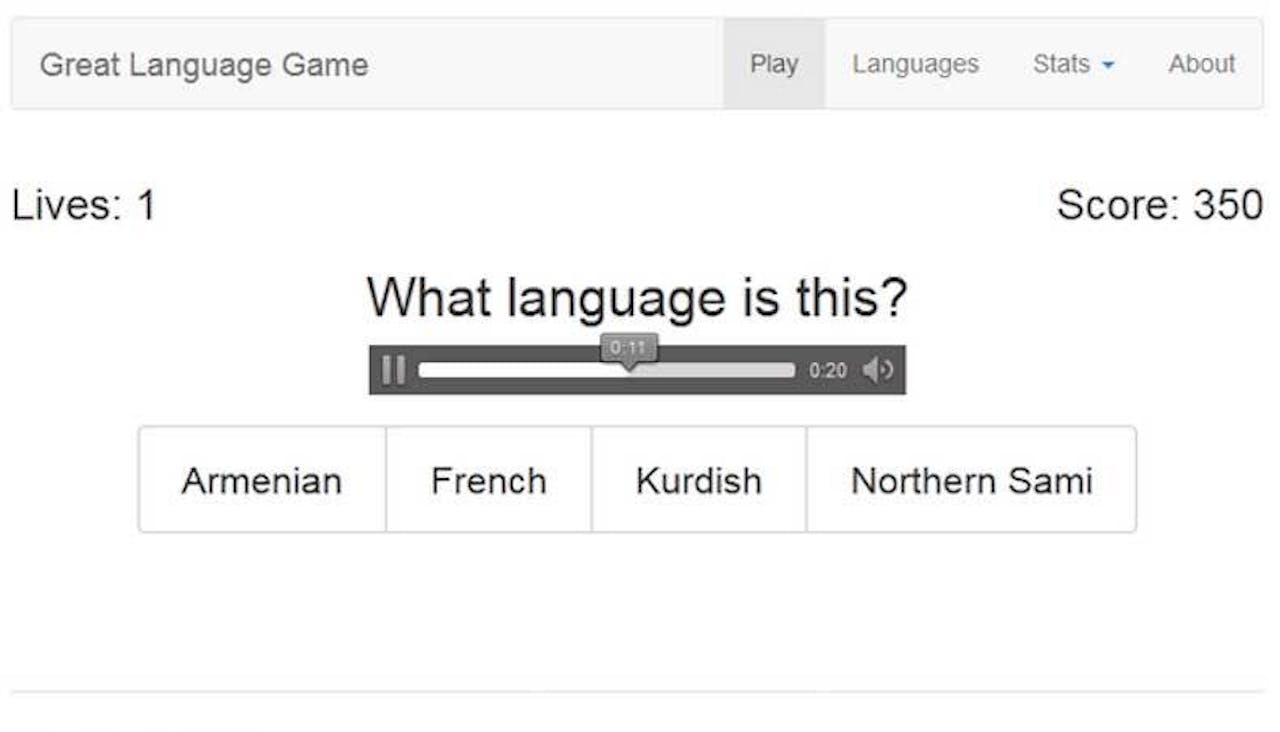
Spelers van The Great Language Game moeten aangeven welke taal ze horen. Elke speler heeft drie levens: na drie fouten stopt het spel. Na elke drie correcte antwoorden komt er een extra antwoordmogelijkheid bij, oplopend tot maximaal elf.
Skirgard et al, 2017“Dit is de eerste keer dat we nauwkeurig kijken naar de perceptie van mensen”, vertelt Seán Roberts, die als onderzoeker aan het Max Planck Instituut betrokken was bij de analyse. “Een van de fundamentele theorieën in de taalwetenschap stelt dat talen uit elkaar zullen drijven en anders zullen klinken als ze gescheiden zijn in tijd of ruimte.” Taalkundigen bestuderen daarom factoren als de taalgeschiedenis en overeenkomstige woorden en klanken als ze talen onderling vergelijken. Uit de analyse van Roberts en zijn collega’s blijkt echter dat niet-taalkundige factoren een grotere invloed hebben op de score van spelers.
Bekende taal sneller herkend
Spelers van The Great Language Game geven gemiddeld in 70 procent van de gevallen het juiste antwoord. Vooral talen waarover veel wordt geschreven, worden goed geraden: hoe vaker de taal genoemd wordt in Google Books, de immense gedigitaliseerde bibliotheek van Google, hoe vaker mensen de taal herkennen. Ook de economische macht van het land waarin de taal wordt gesproken, heeft relatief veel invloed. Iets minder groot is de invloed van het aantal landen waarin de taal wordt gesproken of het aantal sprekers. Net als de mate waarin je aan de naam van de taal kunt afleiden waar deze gesproken wordt (de ‘transparantie’). Voor Schots-Gaelisch is dit bijvoorbeeld een stuk makkelijker dan voor Shona (Zimbabwe).
In onderstaande afbeelding is te zien hoe vaak talen met elkaar verward worden. Hoe langer het meest directe pad is tussen twee talen, hoe kleiner de kans is op onderlinge verwarring. Omdat taal A niet precies even vaak met taal B wordt verward als andersom, is dit netwerk gebaseerd op de gemiddelde verwisseling tussen twee talen.
Op verzoek pakt Roberts de ruwe data er nog even bij: “Nederlands wordt het vaakst verward met Deens, net iets meer dan met het Schots-Gaelisch, en het minst met Spaans. Andersom worden het Jiddisch en het Duits het vaakst aangehoord voor Nederlands.” De grootste voorspellende factor van verwarring blijkt geografische afstand: mensen kunnen talen beter uit elkaar houden als de landen waar ze gesproken worden ver uit elkaar liggen.
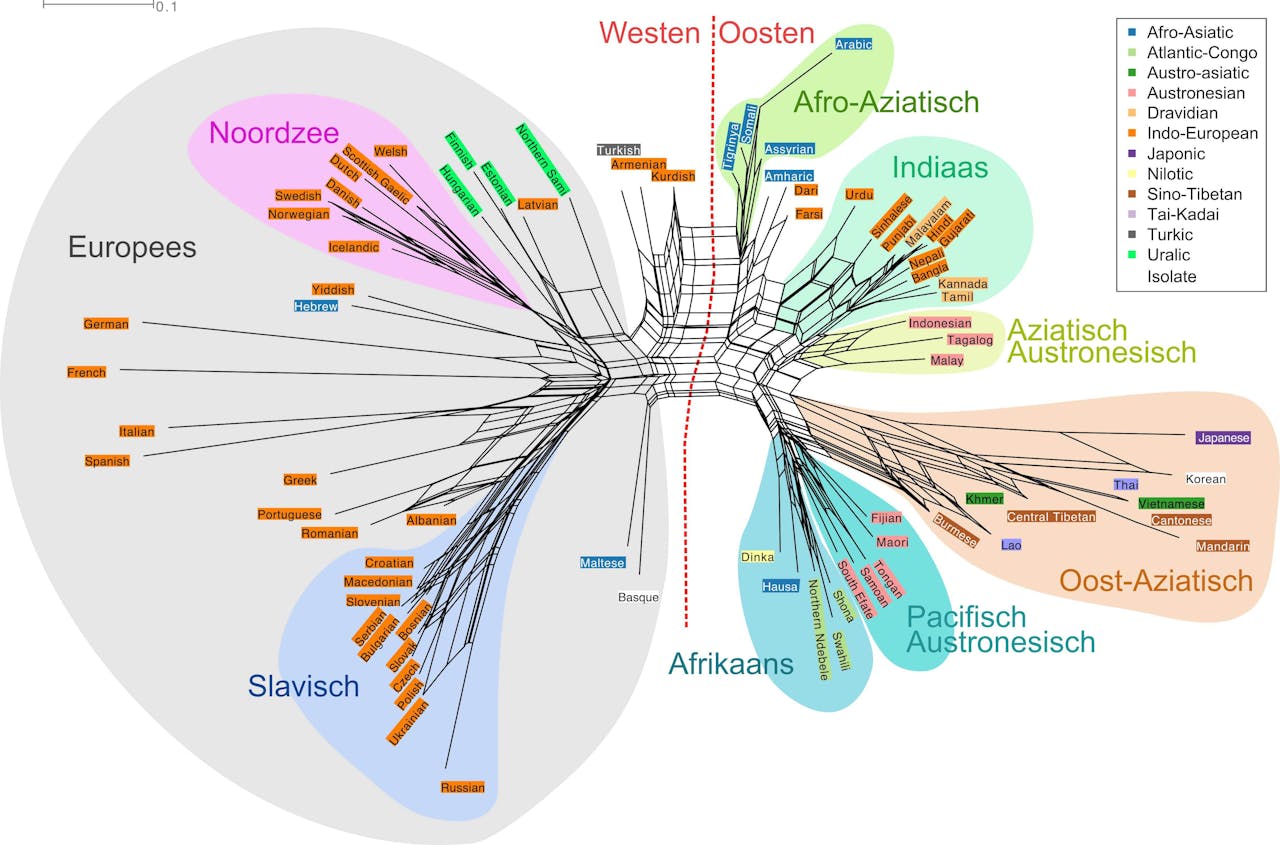
De lengte van de kortst mogelijke route tussen twee talen geeft aan hoe groot de kans is dat deze talen onderling verward worden. Een korte afstand betekent een grote kans op verwarring. Als alle spelers perfect zouden spelen, dan zou het netwerk eruitzien als een ster. Hier zie je echter duidelijk clusters van talen die dicht bij elkaar zijn weergegeven, en dus relatief vaak met elkaar verwisseld werden. De grootste tweedeling is tussen de Europese en de overige talen.
Klik linksboven in de afbeelding voor een vergroting.
Contacten over zee
Het is opvallend dat de talen die worden gesproken rond de Noordzee in het netwerk samen een cluster vormen van vaak verwisselde talen. “Het Welsh en Schots-Gaelisch maken deel uit van de Keltische tak van de Indo-Europese taalfamilie, terwijl het Nederlands en Deens bij de Germaanse tak horen. Waarom wordt het Nederlands dan niet vaker verward met bijvoorbeeld het Duits?” vraagt Roberts zich verwonderd af. Misschien komt het doordat al deze talen grenzen aan de Noordzee, suggereert hij. “De sprekers hebben wellicht onderling veel handelscontact gehad, waardoor de talen in de laatste duizend jaar meer op elkaar zijn gaan lijken. We zien dus eigenlijk twee soorten geschiedenis: die van de hele lange termijn, waardoor het Nederlands verschilt van het Japans, en een meer recente geschiedenis waarin talen weer met elkaar in contact kwamen.”
Dat kan ook verklaren waarom het Nederlands zo vaak wordt aangehoord voor Deens. Tijdens de middeleeuwen was er veel contact tussen de verschillende Hanzesteden rond de Oost- en Noordzee, die samenwerkten op het gebied van handel. In die tijd heeft het Deens ruim 1500 Nedersaksische woorden overgenomen.
“Al met al blijken mensen over veel meer talenkennis te beschikken dan we hadden verwacht. Mensen zijn hier echt goed in!”, stelt Roberts. “In veel taalwetenschappelijke experimenten werken we met proefpersonen die alleen Engels spreken, om zo onverwachte effecten te voorkomen. Maar misschien bestaan er eigenlijk maar weinig mensen die écht eentalig zijn.”
Nieuw spel
De onderzoekers erkennen dat hun dataset niet compleet genoeg is om rotsvaste conclusies te kunnen trekken. Zo zitten er relatief veel Europese talen in het spel: 39 van de 78 talen maken deel uit van de Indo-Europese taalfamilie. Talen uit Noord- en Zuid-Amerika ontbreken zelfs helemaal. “Verder weten we alleen uit welke landen de spelers komen, verder niets”, vertelt Roberts. Bijna 90 procent van de spelers komt uit Europa of Noord-Amerika – het merendeel van hen zal al geïnteresseerd zijn in taal. “Het effect van ervaring hebben we geprobeerd te controleren door sessies waarin werd gevraagd naar een taal uit het land van de speler niet mee te nemen in de analyse.”
Samen met een van de andere auteurs heeft Roberts daarom een nieuwe game ontwikkeld die deze zwakke punten ondervangt. “LingQuest verzamelt meer informatie van de spelers, zoals taalachtergrond, leeftijd en geslacht. Daarnaast zitten er ook verschillende kleine, inheemse talen in – we zijn benieuwd hoe mensen daarop reageren.” In LingQuest, dat is ontwikkeld binnen het Language in Interaction-project, selecteren de spelers niet de juiste naam van een taal, maar een audiofragment in dezelfde taal. Zo kan je het spel ook spelen als je geen ster bent in het benoemen van talen. Roberts: “Tot nu toe is LingQuest zo’n zesduizend keer gespeeld. Dat is nog niet genoeg voor een goede analyse, dus we hopen op meer spelers.”
'%20fill='%23000'%3e%3cpath%20d='M1.28%2022.5c-.505%200-.826-.018-.862-.018a.44.44%200%2001-.238-.792l2.425-1.778A8.266%208.266%200%2001.326%2014.22c0-4.559%203.71-8.268%208.268-8.268a8.269%208.269%200%20018.087%206.556c.119.559.176%201.135.176%201.716%200%204.554-3.705%208.263-8.263%208.263-.907%200-1.804-.15-2.667-.44-1.782.392-3.608.458-4.646.458V22.5zM8.595%206.83c-4.075%200-7.388%203.313-7.388%207.388%200%202.055.867%204.03%202.376%205.416.097.088.15.216.14.348a.448.448%200%2001-.18.33L1.774%2021.61c1.06-.022%202.609-.119%204.083-.458a.468.468%200%2001.246.013%207.414%207.414%200%20002.49.432c4.07%200%207.384-3.314%207.384-7.384a7.385%207.385%200%2000-6.41-7.322%207.849%207.849%200%2000-.973-.06z'/%3e%3cpath%20d='M20.944%2013.102c-.775%200-2.139-.049-3.48-.34-.37.124-.758.216-1.154.27a.44.44%200%2001-.492-.344%207.395%207.395%200%2000-6.253-5.795.44.44%200%2001-.383-.462A6.287%206.287%200%200115.462.5c3.334%200%206.296%202.825%206.296%206.296%200%201.571-.594%203.09-1.65%204.242l1.711%201.254a.439.439%200%2001-.238.792c-.03%200-.263.013-.637.013v.005zm-3.507-1.237c.03%200%20.066%200%20.097.009.941.216%201.918.3%202.675.33l-1.034-.761a.448.448%200%2001-.18-.33.431.431%200%2001.14-.348%205.412%205.412%200%20001.743-3.969A5.421%205.421%200%200015.46%201.38a5.407%205.407%200%2000-5.363%204.708%208.275%208.275%200%20016.48%206.002c.243-.053.48-.12.71-.198a.428.428%200%2001.149-.027z'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='prefix__clip0_1886_150885'%3e%3cpath%20fill='%23fff'%20transform='translate(0%20.5)'%20d='M0%200h22v22H0z'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e) Reageer
Reageer