

Woordbetekenissen liggen opgeslagen verspreid over ons hele brein, in groepjes van woorden die inhoudelijk bij elkaar horen. Dit blijkt uit onderzoek van Amerikaanse wetenschappers. Op een interactief 3D-brein hebben zij de locaties van vele duizenden woorden in kaart gebracht.
Als je luistert naar een verhaal worden verschillende delen in je brein geactiveerd. De plek van de activatie van de woordbetekenis is afhankelijk van het woord. Neuropsychologen van de universiteit van Californië hebben een hersenatlas met meer dan tienduizend woordbetekenissen gepubliceerd. Met twaalf verschillende kleuren zijn de woorden onderverdeeld in evenzoveel inhoudelijke categorieën. Zo vallen thousand en quarter in de categorie ‘getallen’ en husband en sister in de categorie ‘sociaal’.
Eén woord kan op verschillende plekken in het brein voor activatie zorgen. Het woord top bijvoorbeeld, zorgt voor activatie in een gebiedje voor kledingstukken. Maar ook in een regio met woorden voor getallen en maten, en in een regio met gebouwen en plaatsen.
Online interactieve 3D-kaart
Om de kaart te kunnen maken lagen zeven proefpersonen ieder twee uur lang in een fMRI-scanner, luisterend naar waargebeurde verhalen. De onderzoekers registreerden ondertussen wanneer welke hersengebieden extra zuurstofrijk bloed aangevoerd kregen, en dus actief waren. Door deze registratie naast de uitgeschreven verhalen te leggen, konden de onderzoekers een model ontwikkelen dat voorspelt welk hersenbiedje actief wordt bij welk woord.
Vervolgens controleerden ze de voorspellingen van het model bij een nieuwe fMRI-meting met een nieuw verhaal. Voor verschillende gebieden in zowel de linker- als de rechterhersenhelft bleken de voorspellingen overtuigend te kloppen. De onderzoekers hebben de woorden opgenomen in een online interactieve 3D-kaart waarin ook per gebiedje de betrouwbaarheid is weergegeven.
“Dit onderzoek laat prachtig zien hoe complexe analysemethoden kunnen helpen om het mysterie van het menselijk brein te ontrafelen,” aldus Irina Simanova, onderzoeker in het project Language in Interaction. Simanova was niet bij het onderzoek betrokken. “Misschien kan deze methode ook gebruikt worden om andere aspecten van taal in het brein in kaart te brengen, zoals grammatica of klanken. Of misschien zelfs om de betekenis van innerlijke spraak te ontcijferen.”
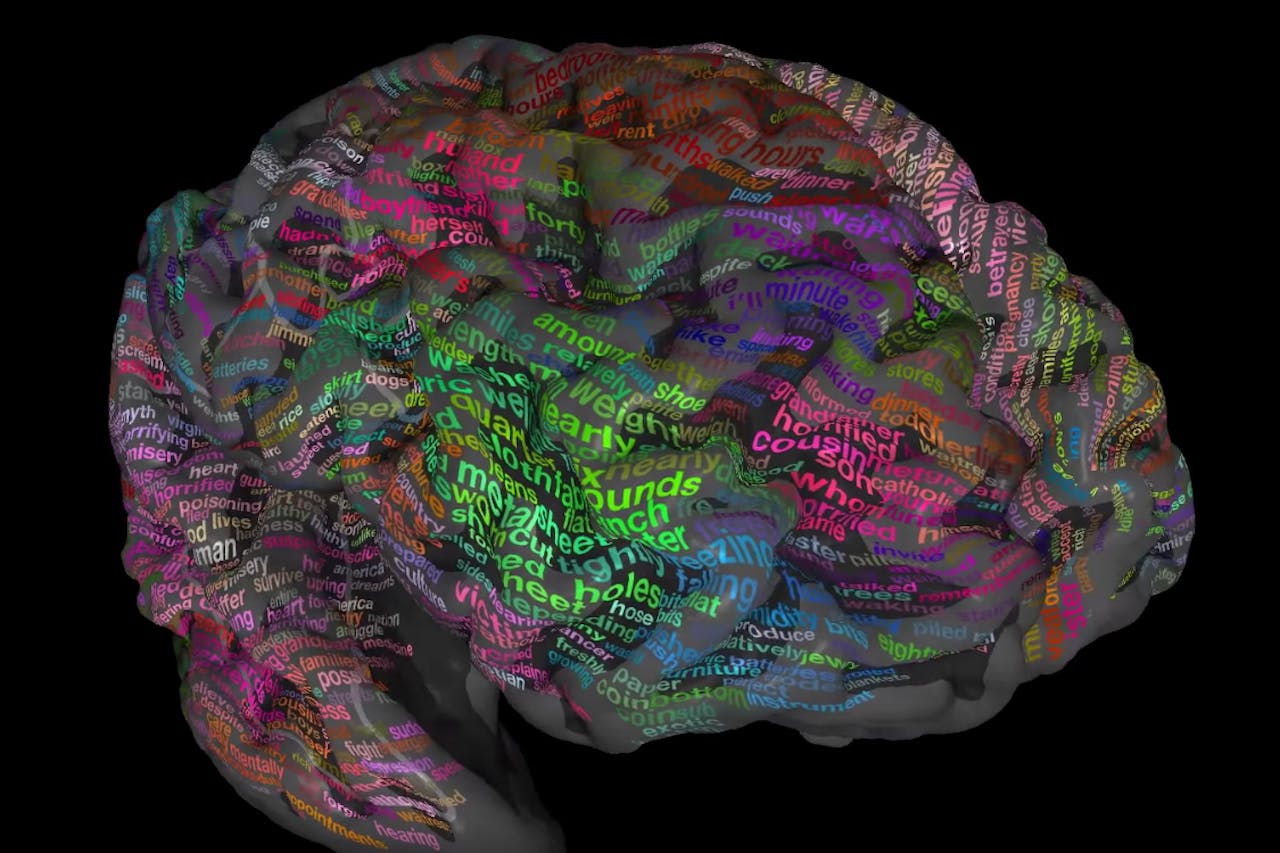
De breinatlas met woordbetekenissen is te bekijken via deze site. Hier kun je het brein roteren en van dichtbij bekijken. Als je een gebiedje selecteert, zie je welke twintig woorden daar het sterkst aan verbonden zijn. Ook kun je het brein opblazen of helemaal gladstrijken, zodat je de gebieden in de groeven beter kunt zien.
UC BerkeleyTaal niet alleen links
Zeven proefpersonen is natuurlijk behoorlijk weinig. Normaal gesproken laten onderzoekers veel meer proefpersonen een veel kleinere taak uitvoeren, zodat ze kunnen uitsluiten dat individuele variatie een vertekend beeld van de hersenactiviteit geeft. Maar volgens Alexander Huth, hoofdauteur van het in Nature gepubliceerde onderzoek, gaan door het middelen van al die proefpersonen juist de belangrijke details verloren. Het algoritme dat hij gebruikte om de algemene hersenatlas te maken, berekent geen gemiddelde, maar zoekt naar contrasten tussen proefpersonen om zo de belangrijkste algemene kenmerken uit de data te halen.
Opvallend is dat de onderzoekers weinig variatie vonden tussen de proefpersonen, wat er volgens hen op wijst dat de aangeboren anatomische structuur bepalend is voor de organisatie van de geleerde woordbetekenissen. Niemand leert zijn moedertaal op precies dezelfde manier en toch lijken de ‘breinatlassen’ sterk op elkaar. Verder viel de onderzoekers op dat de woordbetekenissen over de hele hersenschors gelokaliseerd zijn, vrijwel gelijk over beide hersenhelften. En dus niet alleen in de linker hersenhelft, waar volgens traditionele, inmiddels veelal achterhaalde theorieën het taalvermogen zou zijn gehuisd.
“De bevindingen sluiten mooi aan bij de al breed geaccepteerde embodiment-theorie,” zegt Simanova. “In de gebieden die gericht zijn op een specifieke functie, zoals visuele waarneming of emotie, worden ook de aan die functie gerelateerde woorden gerepresenteerd.” Zo liggen rond de visuele schors bijvoorbeeld veel woorden met een visuele betekenis, zoals colour en stripes.
Andere talen
De breinatlas van woordbetekenissen is nu volledig gebaseerd op moedertaalsprekers van het Engels die naar waargebeurde verhalen luisterden. In vervolgonderzoeken willen de onderzoekers deze data vergelijken met andere data, bijvoorbeeld van andere soorten teksten, andere talen en ook gebarentaal. Wellicht levert dat een hele andere verdeling over de hersenschors op. Verder willen de onderzoekers deze methode gebruiken om te kijken naar de verschillende locaties van andere aspecten van taalverwerking, zoals het waarnemen van klanken en het begrijpen van grammatica.
'%20fill='%23000'%3e%3cpath%20d='M1.28%2022.5c-.505%200-.826-.018-.862-.018a.44.44%200%2001-.238-.792l2.425-1.778A8.266%208.266%200%2001.326%2014.22c0-4.559%203.71-8.268%208.268-8.268a8.269%208.269%200%20018.087%206.556c.119.559.176%201.135.176%201.716%200%204.554-3.705%208.263-8.263%208.263-.907%200-1.804-.15-2.667-.44-1.782.392-3.608.458-4.646.458V22.5zM8.595%206.83c-4.075%200-7.388%203.313-7.388%207.388%200%202.055.867%204.03%202.376%205.416.097.088.15.216.14.348a.448.448%200%2001-.18.33L1.774%2021.61c1.06-.022%202.609-.119%204.083-.458a.468.468%200%2001.246.013%207.414%207.414%200%20002.49.432c4.07%200%207.384-3.314%207.384-7.384a7.385%207.385%200%2000-6.41-7.322%207.849%207.849%200%2000-.973-.06z'/%3e%3cpath%20d='M20.944%2013.102c-.775%200-2.139-.049-3.48-.34-.37.124-.758.216-1.154.27a.44.44%200%2001-.492-.344%207.395%207.395%200%2000-6.253-5.795.44.44%200%2001-.383-.462A6.287%206.287%200%200115.462.5c3.334%200%206.296%202.825%206.296%206.296%200%201.571-.594%203.09-1.65%204.242l1.711%201.254a.439.439%200%2001-.238.792c-.03%200-.263.013-.637.013v.005zm-3.507-1.237c.03%200%20.066%200%20.097.009.941.216%201.918.3%202.675.33l-1.034-.761a.448.448%200%2001-.18-.33.431.431%200%2001.14-.348%205.412%205.412%200%20001.743-3.969A5.421%205.421%200%200015.46%201.38a5.407%205.407%200%2000-5.363%204.708%208.275%208.275%200%20016.48%206.002c.243-.053.48-.12.71-.198a.428.428%200%2001.149-.027z'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='prefix__clip0_1886_150885'%3e%3cpath%20fill='%23fff'%20transform='translate(0%20.5)'%20d='M0%200h22v22H0z'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e) Reageer
Reageer