

Software die geen zwarte gezichten herkent of aanslaat op mensen met een tweede nationaliteit. Algoritmes blijken regelmatig te discrimineren. Hoe kunnen we dit stoppen en het proces omkeren? NEMO Kennislink sprak met twee AI-specialisten die het vertrouwen van de burger willen terugwinnen.
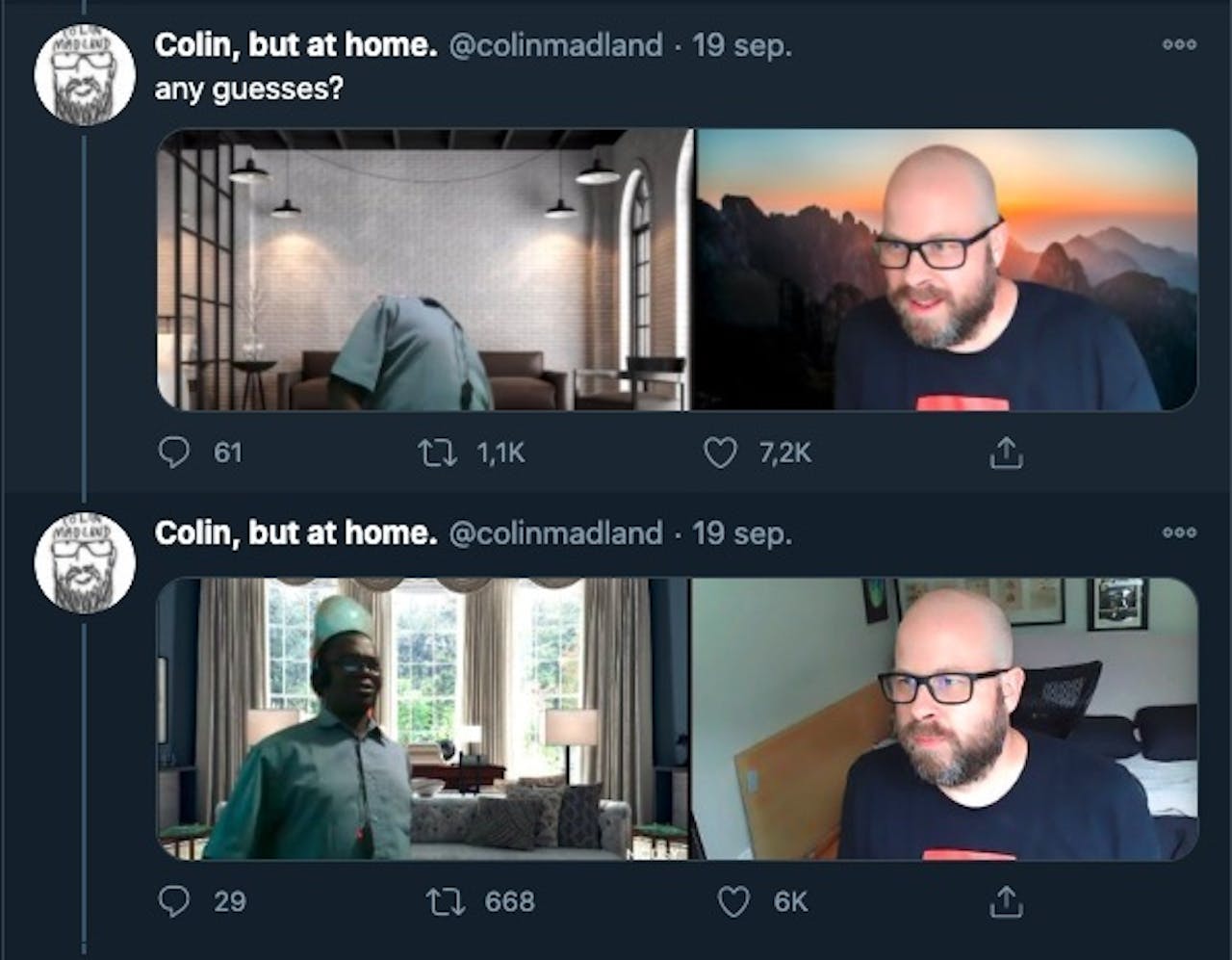
Een zwarte collega van de Canadese promovendus Colin Madland wilde in september zijn virtuele achtergrond aanpassen tijdens een Zoom-meeting. Maar het gezichtsherkenningsalgoritme van Zoom herkende zijn gezicht niet. Pas toen hij voor een lichte wereldbol ging staan, herkende de software zijn hoofd en kreeg hij de gewenste achtergond. Toen Madland dit deelde op Twitter, kwam de volgende misstand aan het licht: het Twitter-algoritme verkleinde de foto en knipte de zwarte man er zelfs helemaal uit. Artificiële Intelligentie (AI) kampt dus met bepaalde vooroordelen.
Neuro-informaticus Sennay Ghebreab doet aan de Universiteit van Amsterdam onderzoek naar manieren waarop we algoritmes kunnen ontwikkelen die niet discrimineren. Zelf werd hij als zwarte man eind jaren 2000 niet herkend door een automatische draaideur, die zijn witte collega’s wel naar buiten liet. Het ‘draaideurincident’ inspireerde hem om onderzoek te doen naar mechanismen van vooroordelen en discriminatie binnen de neuro-informatica, een combinatie van neuro- en computerwetenschappen. Die twee hebben veel gemeen: “AI werkt net als ons brein. Ook ons brein is een patroonherkenner, een discriminator.”
Bias zit in alle facetten
Algoritmes worden getraind op basis van grote hoeveelheden data. En die data zijn afkomstig van mensen die per definitie vooroordelen (bias) hebben. Het is dus niet zo gek dat die grote databestanden ook een zekere bias bevatten. Soms gaat het daarbij om schadelijke vooroordelen, legt Ghebreab uit. Die kunnen ertoe leiden dat algoritmes mensen op oneigenlijke gronden benadelen, oftewel discrimineren. Want als de data al schadelijke vooroordelen bevatten, komt dat als een boemerang terug in alle facetten van de ontwikkeling van een algoritme.
“Om algoritmes te ontwikkelen selecteren de ontwikkelaars een deel van die data: daar zit ook een bias in. Dat gebeurt vaak onbewust of puur uit gemak: je hebt immers te maken met een deadline et cetera. En dan zitten er ook nog bepaalde beslispatronen in de algoritmes. Die houden er bijvoorbeeld geen rekening mee dat er veel meer data zijn over mannen dan over vrouwen. En door sommige statistische methoden kan die ongelijkheid in de data ook nog eens worden versterkt. Tot slot kan er ook nog bias optreden in het gebruik en de toetsing van algoritmes.”

De toeslagenaffaire bij de belastingdienst ontstond doordat men gegevens over tweede nationaliteit van mensen ging gebruiken in algoritmen die risicogroepen moesten opsporen.
CC0 (publiek domein)Dat algoritmes vaak discrimineren verbaast de neuro-informaticus dan ook niet. En dat er nu van alles misgaat bij algoritmes die op grotere schaal worden ingezet, ziet hij als een kans om algoritmes te verbeteren. Ghebreab: “Er is zoveel doemdenken. Data, AI, algoritmes, big tech: dat is de connectie die men nu maakt. Maar het is goed dat we maatschappelijke problemen kunnen blootleggen door te onderzoeken op welk punt in het proces er iets is misgegaan.”
Als voorbeeld noemt de onderzoeker de toeslagenaffaire bij de belastingdienst. Daarbij werden duizenden ouders die gebruikmaakten van kinderopvangtoeslag onterecht als fraudeur aangepakt. “Dat is tot op een zekere hoogte terug te voeren tot data over ‘tweede nationaliteit’. Algoritmen werd aangeleerd dat het hebben van een tweede nationaliteit een risico vormt. Nu dat boven water is, gaan ze er iets aan doen. Ze gaan nu beter nadenken over de kenmerken van mensen die ze willen vastleggen.”
Interdisciplinaire onderzoeksteams
Behalve met het verbeteren van bestaande AI-systemen, houdt Ghebreab zich ook bezig met het ontwikkelen van nieuwe systemen voor het bevorderen van kansengelijkheid. Hiervoor werkt hij met een divers onderzoeksteam. In zijn Civic AI Lab dat onlangs is opgericht, werken wetenschappers uit heel verschillende disciplines met elkaar samen: sociale wetenschappers, filosofen, juristen en AI-experts. Maar ook wil hij burgers betrekken in zijn onderzoek. Niet alleen door hen te informeren wat voor onderzoek ze doen, maar ook door hen te bevragen.

Neuro-informaticus Sennay Ghebreab: “We moeten het vertrouwen van burgers in AI zien terug te winnen met kleine initiatieven.”
Pixabay CC0Als voorbeeld noemt hij een project dat recentelijk is gestart over mobiliteitsarmoede. In Amsterdam bewegen niet alle groepen even makkelijk door de stad en het is niet helemaal duidelijk wat de reden hiervoor is. “Om hier een antwoord op te krijgen is het belangrijk om met burgers in gesprek te gaan. Maar burgers erbij betrekken is natuurlijk het moeilijkst van alles, omdat ze in dit geval niet heel veel weten over AI en er ook veel doemdenken is over AI in de beeldvorming in de media. We moeten dus eerst het vertrouwen zien terug te winnen. Dat doen we door mensen te laten zien dat we hun data gebruiken om oplossingen te vinden voor hun eigen welbevinden. Met de inzet van AI krijgen we inzicht in welke delen van de stad er sprake is van mobiliteitsarmoede. Vervolgens kunnen we kijken waar dat aan ligt en wat we eraan kunnen doen. Het is dus anders dan de grote techbedrijven die de burger alleen maar als onderdeel van hun verdienmodel zien.”
AI for social good
Daarmee past de onderzoeksmethode van Ghebreab in een bredere trend die in opkomst is: ‘AI for social good’. Een groeiende groep universiteiten en tech-companies houdt zich bezig met het verzamelen van data die terug worden gegeven aan de gemeenschap. “Als je blijft hangen in de gedachte ‘men kan misbruik maken van mijn data’ dan blijf je hangen in de situatie van nu. Bovendien geven mensen al massaal hun data weg, maar dan vooral in de richting van de big tech.”
Anders dan de big techbedrijven die werken met ‘one size fits for all’-algoritmes, zet Ghebreab liever in op ‘bottom-up’-AI: lokaal en kleinschalig experimenteren, en als het goed werkt opschalen. Op die manier kun je voorkomen dat een fout in een algoritme veel mensen benadeelt. Dat betekent overigens ook dat er ruimte moet zijn om veelvuldig te experimenteren. Vandaar dat hij niet voor al te strenge regulering is. “Regelgeving voor de bigtechbedrijven is natuurlijk heel belangrijk. Maar je moet ook voorkomen dat je alles zo reguleert dat kleine initiatieven geen zuurstof meer hebben.”
Meer bewustwording
Een vergelijkbaar initiatief is het Cultural AI Lab: een samenwerking van verschillende universiteiten en cultureel erfgoedinstellingen. Marieke van Erp is als leidinggevende van het Digital Humanities Lab (KNAW Humanities Cluster) een van de trekkers van dit nieuwe lab. Ook zij werkt met een multidisciplinair team: een combinatie van AI-experts, geesteswetenschappers en museumprofessionals. Het onderzoek moet nog van start gaan, maar bias in data speelt een belangrijke rol. In een van de projecten gaan ze kijken naar bias in museumcollecties. “Die zijn soms over honderden jaren gevormd, en dus ook vanuit koloniale perspectieven”, zegt Van Erp.
Het Rijksmuseum heeft in 2015 al een aantal bordjes vervangen, dus woorden als ‘hottentot’ of ‘bosneger’ kom je niet meer tegen. Het Nationaal Museum voor Wereldculturen heeft zelfs een hele woordenlijst opgesteld met mogelijk gevoelige woorden en suggesties voor alternatieven. Met machine learning willen Van Erp en haar collega’s nu nog meer termen in de collecties op gaan sporen die denigrerend zijn. “Dit doen we door de computer naar de context te laten kijken van denigrerende woorden die al bekend zijn. Op die manier leert de computer zulke contexten te herkennen. De computer zet dan bijvoorbeeld een vlaggetje bij passages waarvan hij denkt dat het kwetsend taalgebruik is. Vervolgens beoordelen de museumcuratoren of dit ook werkelijk zo is.”
Het is overigens niet zo dat de onderzoekers en musea die gevoelige termen willen gaan uitvlakken, benadrukt Van Erp. “We willen ze vooral zichtbaar maken. Dat is ook wat musea nu al doen. Het tropenmuseum doet er bijvoorbeeld alles aan om aan het publiek uit te leggen hoe we er toen over dachten en nu. Meerdere perspectieven presenteren: zo zorg je voor bewustwording.” Dat sluit goed aan bij de initiatieven van Ghebreab in het basisonderwijs. Al jaren zet hij zich in om de jongste generaties digitale geletterdheid bij te brengen. “Dat is het lezen en schrijven van de toekomst. Als je de grondbeginselen van AI kent, word je nooit gebruikt als speelbal en kun je het op een positieve manier inzetten.”
Op 30 september 2021 gaf Sennay Ghebreab een lezing over inclusieve algoritmes in De Studio van NEMO Science Museum. Luister deze lezing hier terug:
'%20fill='%23000'%3e%3cpath%20d='M1.28%2022.5c-.505%200-.826-.018-.862-.018a.44.44%200%2001-.238-.792l2.425-1.778A8.266%208.266%200%2001.326%2014.22c0-4.559%203.71-8.268%208.268-8.268a8.269%208.269%200%20018.087%206.556c.119.559.176%201.135.176%201.716%200%204.554-3.705%208.263-8.263%208.263-.907%200-1.804-.15-2.667-.44-1.782.392-3.608.458-4.646.458V22.5zM8.595%206.83c-4.075%200-7.388%203.313-7.388%207.388%200%202.055.867%204.03%202.376%205.416.097.088.15.216.14.348a.448.448%200%2001-.18.33L1.774%2021.61c1.06-.022%202.609-.119%204.083-.458a.468.468%200%2001.246.013%207.414%207.414%200%20002.49.432c4.07%200%207.384-3.314%207.384-7.384a7.385%207.385%200%2000-6.41-7.322%207.849%207.849%200%2000-.973-.06z'/%3e%3cpath%20d='M20.944%2013.102c-.775%200-2.139-.049-3.48-.34-.37.124-.758.216-1.154.27a.44.44%200%2001-.492-.344%207.395%207.395%200%2000-6.253-5.795.44.44%200%2001-.383-.462A6.287%206.287%200%200115.462.5c3.334%200%206.296%202.825%206.296%206.296%200%201.571-.594%203.09-1.65%204.242l1.711%201.254a.439.439%200%2001-.238.792c-.03%200-.263.013-.637.013v.005zm-3.507-1.237c.03%200%20.066%200%20.097.009.941.216%201.918.3%202.675.33l-1.034-.761a.448.448%200%2001-.18-.33.431.431%200%2001.14-.348%205.412%205.412%200%20001.743-3.969A5.421%205.421%200%200015.46%201.38a5.407%205.407%200%2000-5.363%204.708%208.275%208.275%200%20016.48%206.002c.243-.053.48-.12.71-.198a.428.428%200%2001.149-.027z'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='prefix__clip0_1886_150885'%3e%3cpath%20fill='%23fff'%20transform='translate(0%20.5)'%20d='M0%200h22v22H0z'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e) Reageer
Reageer