

Justitie gebruikt primitieve en onbetrouwbare methoden om bewijsmateriaal te vergaren uit grote databestanden, zegt data-onderzoeker David Graus. Hij hoopt dat dit niet de manier is waarop de overheid sleepnetten door onze internetdata gaat halen.
Waarschijnlijk gaat menig topcrimineel jarenlang spijt krijgen van zijn blinde vertrouwen in de PGP-telefoons van Ennetcom. In maart 2017 werd bekend dat de Nederlandse justitie anderhalf miljoen e-mails en tekstberichten heeft ontcijferd die met deze telefoons zijn verstuurd. PGP-encryptie is niet te kraken als het goed gebruikt wordt (zie het kader over PGP onderaan dit artikel), en uiteraard geeft Justitie zelf geen details, maar mogelijk is Ennetcom slordig omgesprongen met het genereren van de geheime sleutels voor de telefoons.
In de rechtszaak tegen Naoufal F. (‘Noffel’) speelt bewijsmateriaal uit deze hack een sleutelrol. Noffel wordt er van beschuldigd dat hij een grootschalige drugshandelaar is, en opdracht heeft gegeven tot een liquidatie. Je zou kunnen denken: als hij dat klip en klaar heeft opgetikt in een bericht via zo’n gehackte Ennetcom-telefoon, dan is de zaak rond. Maar zo simpel is het niet.
Laten slapen
Zelfs via die ‘onkraakbare’ telefoons stuurde men vaak berichten waarin mensen schuilnamen hadden, en gevoelige termen als ‘drugs’ of ‘doodschieten’ werden vervangen door woorden als ‘fruit’ en ‘laten slapen’. Althans, dat zegt Justitie, maar de verdediging vindt dat dit eerst nog maar eens bewezen moet worden.
Een ander probleem is dat geen mens die hele database van anderhalf miljoen berichten, afkomstig van ruim dertigduizend afzenders, in z’n geheel kan doorspitten. Dus is er door het Nederlands Forensisch Instituut (NFI) een automatische selectie gemaakt.
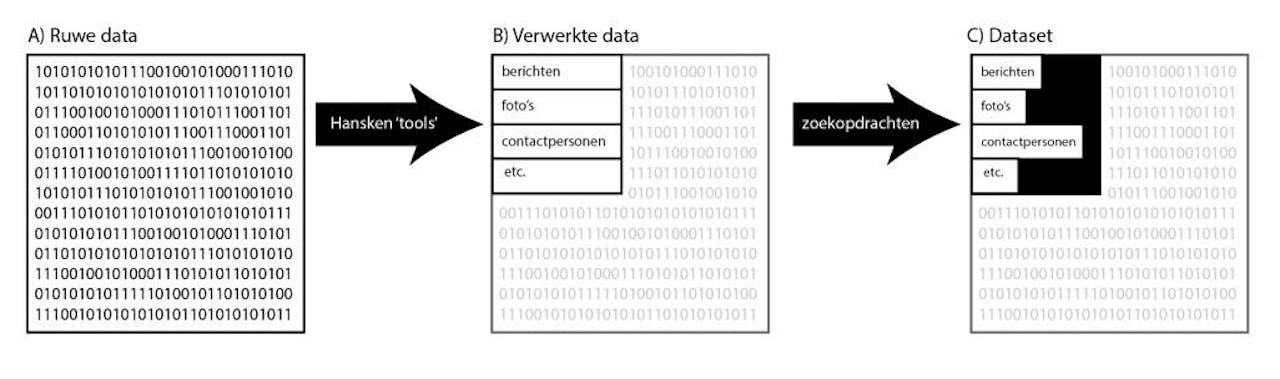
Schets van de twee-traps dataselectie in de rechtszaak tegen Naoufval F. De dataselectie was in feite nog een stuk onoverzichtelijker (zie afbeelding hieronder).
David GrausHet NFI selecteerde eerst met het Google _langdetect_-programma alleen de Nederlandstalige berichten, waardoor ongeveer twee op de drie afvielen. Vervolgens doorzocht het die dataset met Hansken. Dit is een zoekmachine die door het Nederlands Forensisch Instituut (NFI) speciaal ontwikkeld is om grote hoeveelheden data te doorzoeken op mogelijk bewijsmateriaal.
David Graus, aan de Universiteit van Amsterdam gepromoveerd in zoekmachinetechnologie en digitaal forensisch onderzoek, werd door Inez Weski, de advocaat van Noffel ingehuurd. Hij sprak met de betrokken forensisch deskundigen en schreef een rapport over zijn bevindingen. Graus: “Een forensische zoekmachine doet high recall search, en dat is iets heel anders dan de high precision search zoals bijvoorbeeld Google doet.” Van Google wil je dat die de meest relevante hits oplevert, en liever niet heel veel. Maar forensisch onderzoekers willen juist zoveel mogelijk bewijsmateriaal uit de data halen.
Dataset Tandem
Hansken doet dit door simpelweg te zoeken op basis van een lijstje zoektermen die door de gebruiker wordt ingevoerd. In dit geval leverde het NFI namen en bijnamen van verdachten. Dat leverde een dataset op van ongeveer veertigduizend berichten, onder de naam Tandem, waar advocate Weski haar pijlen op richt. Met high recall search is het onvermijdelijk dat je ook grote aantallen irrelevante berichten selecteert. Graus verbaast zich over deze primitieve methode. Volgens hem zijn er al sinds de jaren tachtig betere, contextgerichte methoden ontwikkeld om data op bepaalde onderwerpen te doorzoeken.
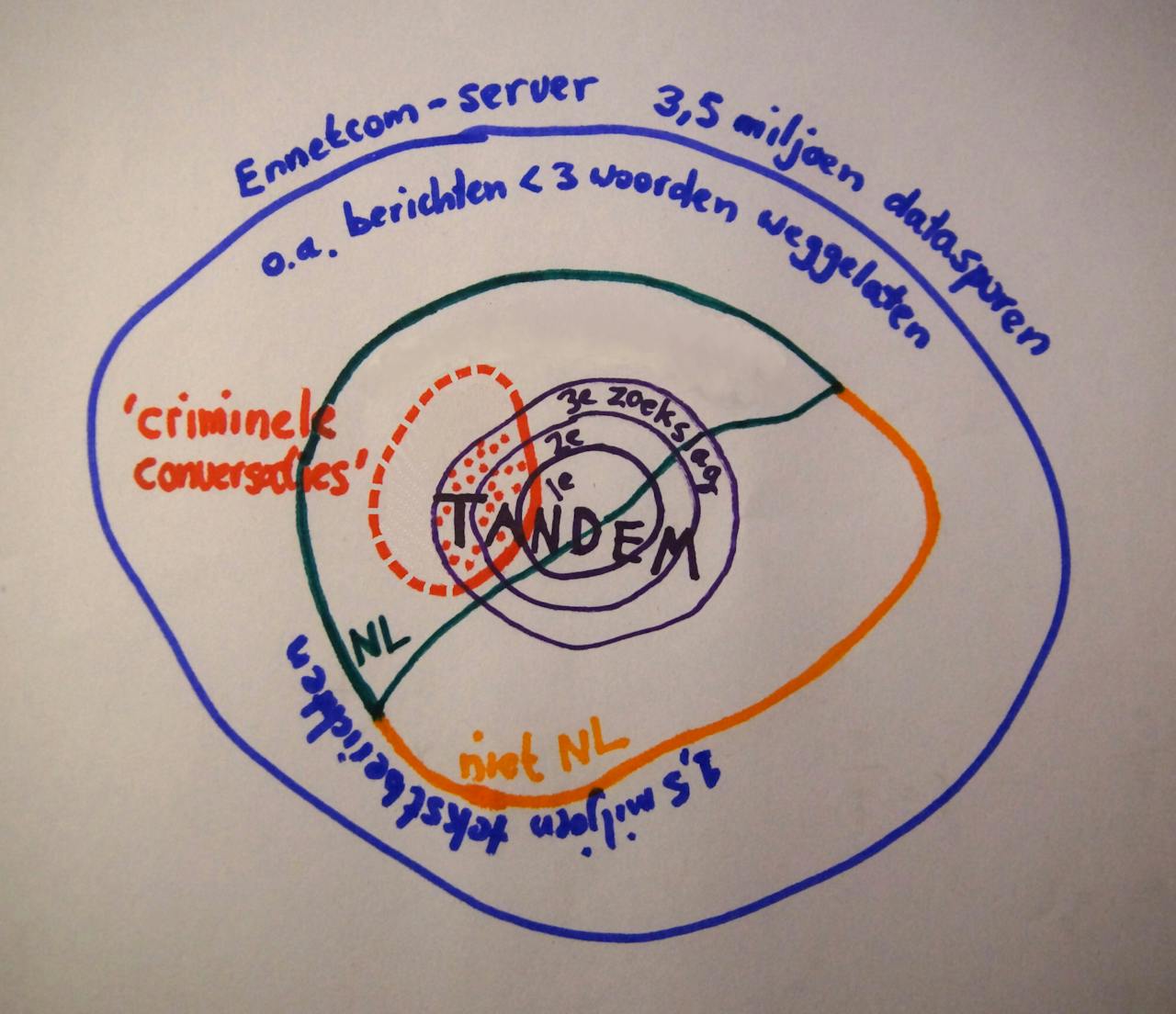
Diagram van de dataselectie door het NFI en het Team High Tech Crime op de Ennetcom-dataset. Het gebied met de rode stippen staat voor het bewijsmateriaal in de zaak tegen Noffel H.
Arnout Jaspers voor NemokennislinkIn feite zijn er drie ‘zoekslagen’ op de Ennetcom-data gedaan: nadat het OM de oogst van de eerste lijst zoektermen had bekeken, gaf de rechter-commissaris nog twee keer toestemming aan het NFI om, in opdracht van het OM, de zoektermen uit te breiden. De Tandem dataset is dus twee keer uitgebreid.
Daarnaast deed het Team High Tech Crime (THTC), een onderdeel van de landelijke politie, een andere selectie op de data, waarmee het beoogde specifiek de ‘criminele conversaties’ uit de Tandem-dataset te vissen. Dat deed het THTC door in alle berichten te zoeken naar een of meer woorden uit een ‘topiclijst’ van 116 termen. Aangezien ook via de Ennetcom-telefoons niemand het expliciet heeft over ‘drugstransport’, ‘huurmoordenaar’ of andere evident criminele zaken, bevat die lijst ook heel alledaagse woorden als ‘hard’, ‘boot’, ‘fruit’, ‘meloen’, ‘vis’ en ‘vrachtwagen’. Hoe het THTC aan die lijst komt is onduidelijk; mogelijk is die handmatig samengesteld op basis van ervaringen van rechercheurs in eerdere onderzoeken.
Criminele conversaties
Om te bewijzen dat hun selectie specifiek de criminele conversaties uit Tandem vist, vermeldt het THTC in de processtukken dat gebruikers met nul hits op deze 116 zoektermen gemiddeld maar 5,6 gesprekken voeren, gebruikers met één hit gemiddeld 9,7 gesprekken, en gebruikers met twee of meer hits gemiddeld 183 gesprekken. Dat zou dan leiden tot de conclusie: “Hoe meer berichten van een adres in de data beschikbaar zijn, hoe duidelijker de mogelijk criminele relevantie van de inhoud van het berichtenverkeer naar voren komt.”
Een ongeldige redenatie, vindt Graus, aangezien de kans dat zulke algemene zoektermen in de berichten van een gebruiker voorkomen sowieso toeneemt naarmate die gebruiker meer berichten verstuurt. Graus: “Als een student van mij dit zou inleveren, zou dit echt niet door de beugel kunnen.”
Graus vraagt zich ook af hoe het zit met ontlastende informatie. Stel, iemand stuurt een bericht waarin hij zegt dat hij X ‘gaat laten slapen’. Dit bericht zal in Tandem terecht komen, maar als uit het antwoord duidelijk wordt dat dit een grapje over X betreft, komt dit dan ook in de dataset?
Een meer juridisch bezwaar is dat niet meer goed na te gaan valt hoe de selectie van Tandem precies tot stand gekomen is. Hansken is namelijk nog steeds in ontwikkeling door het NFI, en gedurende het zich over maanden uitstrekkende onderzoek kwam zo ongeveer iedere drie weken een nieuwe versie uit. Maar in die opeenvolgende veranderingen kregen Graus en de verdediging geen inzage. Graus: “In wezen is Hansken een apparaat dat bewijsmateriaal genereert uit ruwe data, maar het apparaat verandert steeds.”
Boeven vangen
Dat Noffels advocate Weski er alle belang bij heeft om het bewijsmateriaal uit de Ennetcom-hack te ondergraven, zal duidelijk zijn. Maar al kan de selectie van de dataset en de transparantie van de methodes ongetwijfeld beter – zijn dit nu echt bezwaren waar de hardwerkende Telegraaflezer van wakker ligt? Die zal allicht denken: ‘hoe meer boeven je vangt, hoe beter.’
Maar wat zijn ‘boeven’? Graus wijst er op, dat van de 5500 gehackte accounts in de Tandem-dataset, er maar twee of 2 of 3 van belang zijn voor de rechtszaak tegen Naoufal F. Ennetcom is een Canadees bedrijf, en de rechter in Canada stelde als voorwaarde voor het ‘uitleveren’ van de gehackte data, dat de Nederlandse justitie er niet een sleepnet doorheen ging halen om bewijsmateriaal over alle mogelijke wetsovertredingen door alle gebruikers te verzamelen. Dus deze rechtszaak mag geen voorwendsel zijn, om ook bijvoorbeeld zwartspaarders tegen de lamp te laten lopen. Maar wie garandeert dat de Fiod niet over een tijdje ook een kijkje neemt in de Tandem-dataset?
Het automatisch doorzoeken van enorme hoeveelheden data is ook aan de orde bij de extra bevoegdheden die de AIVD krijgt onder de nieuwe Wet op de inlichtingen- en veiligheidsdiensten. Als high recall search op basis van heel algemene zoektermen de norm wordt bij het doorploegen van terabytes aan internetdata, zal dat enorme aantallen valse sporen en onterechte verdenkingen opleveren. Graus: “Je mag hopen dat ze bij de AIVD wat beters hebben.”
- Het NFI verklaart via een woordvoerder dat ze over deze zaak niets kunnen zeggen tegen de media. Het THTC reageert niet op een verzoek om commentaar.
'%20fill='%23000'%3e%3cpath%20d='M1.28%2022.5c-.505%200-.826-.018-.862-.018a.44.44%200%2001-.238-.792l2.425-1.778A8.266%208.266%200%2001.326%2014.22c0-4.559%203.71-8.268%208.268-8.268a8.269%208.269%200%20018.087%206.556c.119.559.176%201.135.176%201.716%200%204.554-3.705%208.263-8.263%208.263-.907%200-1.804-.15-2.667-.44-1.782.392-3.608.458-4.646.458V22.5zM8.595%206.83c-4.075%200-7.388%203.313-7.388%207.388%200%202.055.867%204.03%202.376%205.416.097.088.15.216.14.348a.448.448%200%2001-.18.33L1.774%2021.61c1.06-.022%202.609-.119%204.083-.458a.468.468%200%2001.246.013%207.414%207.414%200%20002.49.432c4.07%200%207.384-3.314%207.384-7.384a7.385%207.385%200%2000-6.41-7.322%207.849%207.849%200%2000-.973-.06z'/%3e%3cpath%20d='M20.944%2013.102c-.775%200-2.139-.049-3.48-.34-.37.124-.758.216-1.154.27a.44.44%200%2001-.492-.344%207.395%207.395%200%2000-6.253-5.795.44.44%200%2001-.383-.462A6.287%206.287%200%200115.462.5c3.334%200%206.296%202.825%206.296%206.296%200%201.571-.594%203.09-1.65%204.242l1.711%201.254a.439.439%200%2001-.238.792c-.03%200-.263.013-.637.013v.005zm-3.507-1.237c.03%200%20.066%200%20.097.009.941.216%201.918.3%202.675.33l-1.034-.761a.448.448%200%2001-.18-.33.431.431%200%2001.14-.348%205.412%205.412%200%20001.743-3.969A5.421%205.421%200%200015.46%201.38a5.407%205.407%200%2000-5.363%204.708%208.275%208.275%200%20016.48%206.002c.243-.053.48-.12.71-.198a.428.428%200%2001.149-.027z'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='prefix__clip0_1886_150885'%3e%3cpath%20fill='%23fff'%20transform='translate(0%20.5)'%20d='M0%200h22v22H0z'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e) Reageer
Reageer