
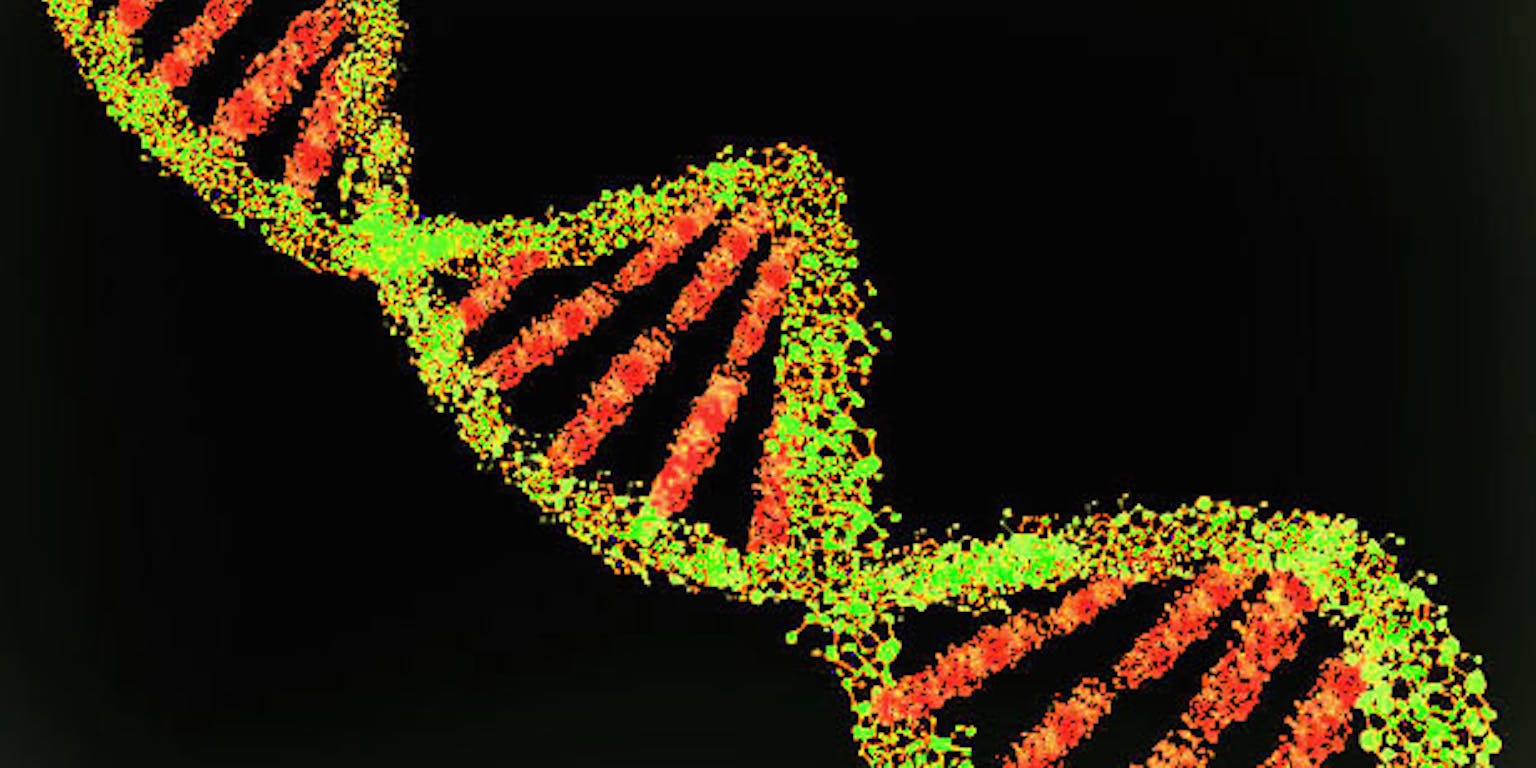
Amerikaanse onderzoekers hebben een nieuw algoritme geschreven waarmee ze grote pakketten data op DNA opslaan. DNA werkt dan als een soort super computergeheugen. Het nieuwe systeem doet het beter dan eerdere pogingen om informatie op DNA op te slaan en blijkt ook nog eens foutloos.
Onze computers houden de enorme groei van data niet lang meer bij. Elke dag creëren wij zo’n 2,5 exabyte of 2.500.000.000 gigabyte aan nieuwe data en dat moeten we ergens opslaan. DNA wordt al jaren gezien als de nieuwe generatie harde schrijven. Een DNA-database neemt veel minder ruimte in beslag, blijft honderden jaren goed en de techniek zal niet snel verouderen.
Niet efficiënt
Helaas is data opslaan op DNA niet zo makkelijk. Onderzoekers schrijven de informatie nog niet efficiënt genoeg op de nucleotiden (de bouwstenen van het DNA) waardoor veel potentiële ruimte verloren gaat. Ook ontstaan er vaak fouten als ze de data weer van het DNA willen halen. Onderzoekers van Columbia University en het New York Genome Center (NYGC) hebben deze problemen nu op een slimme manier opgelost. “Elk mediabestand bestaat uit binaire code, een reeks van enen en nullen. Wij kunnen deze lange reeksen nu zo knippen dat we ze uiteindelijk zonder fouten weer aflezen”, vertelt co-auteur en hoogleraar computerwetenschappen Yaniv Erlich.

Alle digitale berekeningen gaan met enen en nullen.
Christiaan Colen via CC BY-SA 2.0Erlich gebruikt hiervoor een zogenaamd fontein-algoritme. Dit algoritme zorgt er ook voor dat je video’s kunt streamen op je telefoon. Met deze techniek knipt de computer grote bestanden in korte strengen binaire code en verdeelt deze korte strengen willekeurig over zogenoemde ‘druppels’. Vervolgens bindt de computer de code aan de vier nucleotiden waar DNA uit opgebouwd is: de A werd 00, C is 01, G is 10 en T is 1.
Sudoku
Vervolgens verwijdert de computer de lettercombinaties die vaak problemen opleveren bij het kopiëren van het DNA en krijgen alle druppels een streepjescode zodat ze weer in de goede volgorde in elkaar worden gezet. “Omdat het algoritme bepaalde regels gebruikt tijdens het knippen van de code, kunnen we de code ook opbouwen als enkele druppels missen”, legt Erlich uit. Hij vergelijkt het met het maken van een sudoku: “Ook bij sudokus zijn sommige vakken leeg, maar je kunt ze wel weer invullen omdat je de regels kent.”
De onderzoekers maakten een groot bestand met daarin een besturingssysteem van een computer, een Franse film, een Amazon-cadeaukaart, een computervirus, een gouden plaat die ooit meeging in de Pioneer-ruimtesonde en een wetenschappelijk artikel om hun systeem te testen. De 72.000 stukken DNA die de computer uiteindelijk van dit bestand maakte, lieten ze door een bedrijf synthetiseren. En met succes: “Toen we het buisje met DNA met een speciale software weer omzetten naar binaire code konden we alle bestanden weer lezen en gebruiken,” zegt Erlich trots. “We hebben zelfs nog een paar keer kopieën gemaakt, die we elke keer zonder fouten konden gebruiken.”

Misschien slaan we onze data over enkele jaren wel op op DNA.
Karl-Ludwig Poggemann/Flickr.com via CC BY 2.0Een record
De techniek is niet alleen foutloos, maar Erlich en zijn collega’s hebben er ook nog eens een record mee gevestigd: “Met onze techniek zetten we honderd keer meer data op een gram DNA dan voorheen mogelijk was.” Toch denkt Erlich niet dat we binnenkort allemaal een DNA als harde schrijf in onze computer hebben: “Het systeem kost veel geld; we waren 9000 dollar kwijt om het bestand te synthetiseren en af te lezen.” Bovendien zijn er nog wel tekortkomingen: “Je kunt niet makkelijk even een klein dingetje in het bestand aanpassen, dan moet je meteen een hele nieuwe streng DNA maken.”
'%20fill='%23000'%3e%3cpath%20d='M1.28%2022.5c-.505%200-.826-.018-.862-.018a.44.44%200%2001-.238-.792l2.425-1.778A8.266%208.266%200%2001.326%2014.22c0-4.559%203.71-8.268%208.268-8.268a8.269%208.269%200%20018.087%206.556c.119.559.176%201.135.176%201.716%200%204.554-3.705%208.263-8.263%208.263-.907%200-1.804-.15-2.667-.44-1.782.392-3.608.458-4.646.458V22.5zM8.595%206.83c-4.075%200-7.388%203.313-7.388%207.388%200%202.055.867%204.03%202.376%205.416.097.088.15.216.14.348a.448.448%200%2001-.18.33L1.774%2021.61c1.06-.022%202.609-.119%204.083-.458a.468.468%200%2001.246.013%207.414%207.414%200%20002.49.432c4.07%200%207.384-3.314%207.384-7.384a7.385%207.385%200%2000-6.41-7.322%207.849%207.849%200%2000-.973-.06z'/%3e%3cpath%20d='M20.944%2013.102c-.775%200-2.139-.049-3.48-.34-.37.124-.758.216-1.154.27a.44.44%200%2001-.492-.344%207.395%207.395%200%2000-6.253-5.795.44.44%200%2001-.383-.462A6.287%206.287%200%200115.462.5c3.334%200%206.296%202.825%206.296%206.296%200%201.571-.594%203.09-1.65%204.242l1.711%201.254a.439.439%200%2001-.238.792c-.03%200-.263.013-.637.013v.005zm-3.507-1.237c.03%200%20.066%200%20.097.009.941.216%201.918.3%202.675.33l-1.034-.761a.448.448%200%2001-.18-.33.431.431%200%2001.14-.348%205.412%205.412%200%20001.743-3.969A5.421%205.421%200%200015.46%201.38a5.407%205.407%200%2000-5.363%204.708%208.275%208.275%200%20016.48%206.002c.243-.053.48-.12.71-.198a.428.428%200%2001.149-.027z'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='prefix__clip0_1886_150885'%3e%3cpath%20fill='%23fff'%20transform='translate(0%20.5)'%20d='M0%200h22v22H0z'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e) Reageer
Reageer