In mijn eerste blog voor Faces of Science beschreef ik hoe ik in het archief van De Groene Amsterdammer voor het eerst begreep waarom historici zo verzot zijn op de geur van oud papier. Hoewel de meeste historici graag oude boeken besnuffelen, maken stoffige archiefkamers, oud papier en bibliothecarissen in toenemende mate plaats voor websites, pdf bestanden en zoekmachines. Maar hoe spit je nu precies door digitale boeken? Ik neem je mee op avontuur in mijn zoektocht naar historische pareltjes op het web.
Moderne bibliotheken van Alexandrië
Overal op het internet vind je gedigitaliseerde boeken, kranten, tijdschriften, brieven, pamfletten en andere historische bronnen. Maar waar kan je het beste rondneuzen in digitale teksten zonder te verdwalen in een informatieberg? Google Books heeft een uitgebreide collectie digitale boeken, kranten en tijdschriften. Al deze teksten doorzoek je op woord niveau. Met een zogenaamde ngramviewer bekijk je wanneer een bepaald woord voor het eerst in al deze teksten voorkomt (zie hieronder een voorbeeld).
Het Internet Archive, een non-profit organisatie die uiteindelijk het moderne equivalent van de mythische bibliotheek van Alexandrië hoopt te worden, heeft eveneens een enorme collectie van digitaal doorzoekbare boeken, kranten en tijdschriften. Daarnaast archiveren ze ook tv-programma’s, radio-uitzendingen, oude computerspellen (die je via je browser speelt) en internetpagina’s. Bekijk bijvoorbeeld hoe de site van de Tweede Kamer eruit zag in 2002. Nederland heeft een van de beste digitale kranten- en tijdschriftenarchieven ter wereld. Delpher.nl, de site waarmee je de digitale collecties van de Koninklijke Bibliotheek doorzoekt, biedt gratis toegang tot acht miljoen Nederlandse krantenpagina’s. En ook Delpher heeft een ngramviewer (zie hieronder).
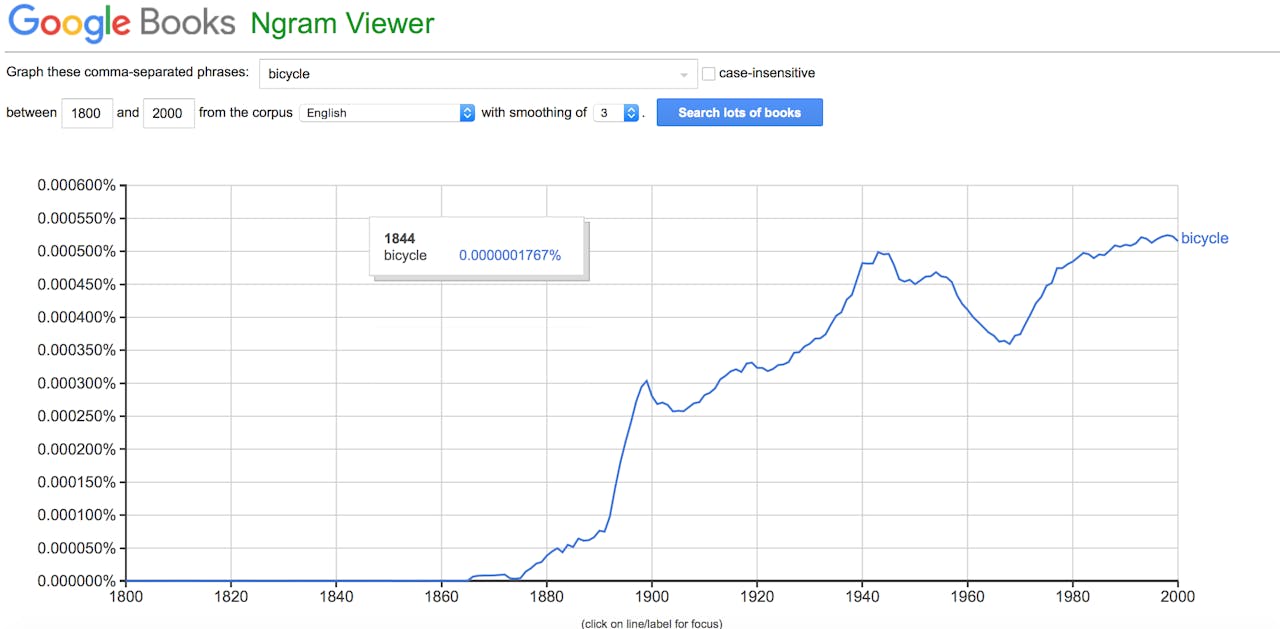
Google Ngramviewer gezocht naar ‘bicycle’ in het volledige Engelstalige corpus.
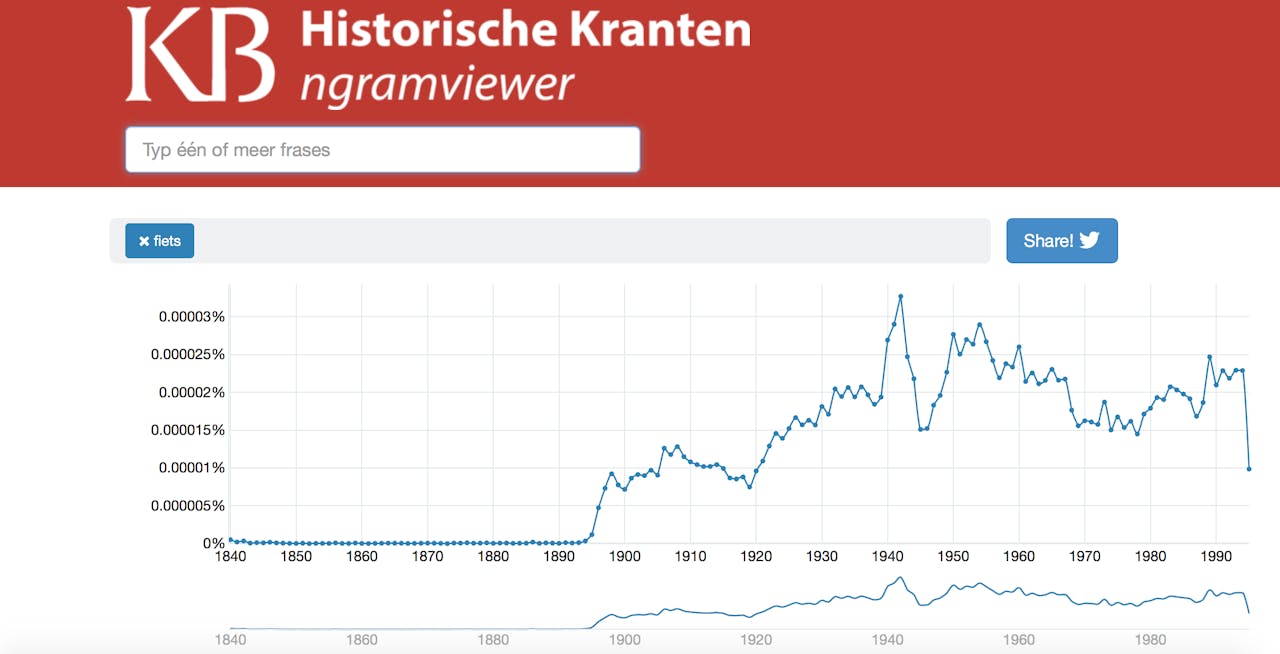
KB Historische Kranten ngramviewer gezocht naar ‘fiets’ in gedigitaliseerde Nederlandse kranten, 1800-2000. De piek rond 1940, het begin van de Duitse bezetting, heeft te maken met de uitzonderlijke grote hoeveelheid kranten uit deze periode in Delpher.
De World Digital Library biedt toegang tot de digitale versies van bijzonder historisch materiaal van over de hele wereld. Bekijk bijvoorbeeld dit Ethiopische manuscript uit de vroege 16de eeuw, of deze afbeeldingen van Indonesische eilanden in de wereldberoemde Nederlandse Atlas Maior van Joan Blaeu (1596–1673)
Grafieken en tabellen: big data voor historisch onderzoek
Wat betekent de toenemende digitalisering van archieven voor historisch onderzoek? De meeste teksten in digitale archieven kunnen op woordniveau doorzocht worden. Dat betekent dat we steeds sneller, steeds grotere corpora (verzamelingen van historische bronnen) kunnen onderzoeken. Deze steeds groter wordende verzameling bronnen, soms aangeduid als ‘big data’, zorgt ervoor dat historici steeds meer kwantitatief onderzoek doen. In plaats van een klein aantal teksten heel erg goed te analyseren (kwalitatief onderzoek) ontdekken we bredere patronen in een grote hoeveelheid teksten, of tussen teksten in verschillende gedigitaliseerde archieven. Op een meer praktisch niveau besparen digitale archieven historici ook veel tijd. Veel ‘archiefonderzoek’ doe je immers vanachter je computer.
Nooit meer oud papier?
Hoeven historici in de toekomst helemaal nooit meer naar een ‘echt’ papieren archief? Dat lijkt onwaarschijnlijk. Ten eerste zorgt digitalisatie voor een aantal problemen. Zo wordt er van veel bronnen maar één editie gedigitaliseerd, waardoor verschillende uitgaves niet met elkaar vergeleken kunnen worden. Daarnaast worden er vaak onderdelen van uitgaves niet gedigitaliseerd, terwijl die juist erg interessant zijn: denk bijvoorbeeld aan de advertenties. Maar misschien wel het belangrijkst: digitalisatie, zowel het scannen als het ontsluiten, is relatief duur. Er blijft altijd historisch bronnenmateriaal over waar te weinig mensen in geïnteresseerd zijn. En hopelijk blijven we dit bewaren in onze oude, vertrouwde papierarchieven!
'%20fill='%23000'%3e%3cpath%20d='M1.28%2022.5c-.505%200-.826-.018-.862-.018a.44.44%200%2001-.238-.792l2.425-1.778A8.266%208.266%200%2001.326%2014.22c0-4.559%203.71-8.268%208.268-8.268a8.269%208.269%200%20018.087%206.556c.119.559.176%201.135.176%201.716%200%204.554-3.705%208.263-8.263%208.263-.907%200-1.804-.15-2.667-.44-1.782.392-3.608.458-4.646.458V22.5zM8.595%206.83c-4.075%200-7.388%203.313-7.388%207.388%200%202.055.867%204.03%202.376%205.416.097.088.15.216.14.348a.448.448%200%2001-.18.33L1.774%2021.61c1.06-.022%202.609-.119%204.083-.458a.468.468%200%2001.246.013%207.414%207.414%200%20002.49.432c4.07%200%207.384-3.314%207.384-7.384a7.385%207.385%200%2000-6.41-7.322%207.849%207.849%200%2000-.973-.06z'/%3e%3cpath%20d='M20.944%2013.102c-.775%200-2.139-.049-3.48-.34-.37.124-.758.216-1.154.27a.44.44%200%2001-.492-.344%207.395%207.395%200%2000-6.253-5.795.44.44%200%2001-.383-.462A6.287%206.287%200%200115.462.5c3.334%200%206.296%202.825%206.296%206.296%200%201.571-.594%203.09-1.65%204.242l1.711%201.254a.439.439%200%2001-.238.792c-.03%200-.263.013-.637.013v.005zm-3.507-1.237c.03%200%20.066%200%20.097.009.941.216%201.918.3%202.675.33l-1.034-.761a.448.448%200%2001-.18-.33.431.431%200%2001.14-.348%205.412%205.412%200%20001.743-3.969A5.421%205.421%200%200015.46%201.38a5.407%205.407%200%2000-5.363%204.708%208.275%208.275%200%20016.48%206.002c.243-.053.48-.12.71-.198a.428.428%200%2001.149-.027z'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='prefix__clip0_1886_150885'%3e%3cpath%20fill='%23fff'%20transform='translate(0%20.5)'%20d='M0%200h22v22H0z'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e) Reageer
Reageer