
In de vorige post had ik het over de hoofdvraag van mijn onderzoek: bestaat er zoiets als een hitformule; een recept waarmee je een pop-hit kan schrijven die in het geheugen blijft hangen als een echte ear worm? Nu komen de eerste resultaten binnen, maar hoe schep je duidelijkheid in de datastroom?
De ‘hitformule’ is moeilijk te meten, maar misschien niet onmogelijk. Wij hebben namelijk in de voorbije twee jaar heel wat gegevens verzameld over hoe snel mensen liedjes herkennen, via onze iOS app Hooked! (web-versie) en onze website HookedOnMusic met muziek uit de Britse hitparade door de jaren heen.
Resultaten!
De afgelopen weken hebben we de eerste analyse van deze gegevens afgerond, en opgeschreven in een paper die deze week online komt. De eerste resultaten zijn dus binnen! Maar wat onderzochten we precies? In deze analyse maken we een kaart van alle muziekfragmenten in onze database. Dit deden we door, eerst en vooral, de verschillende akoestische eigenschappen van de fragmenten door de computer uit te laten rekenen. We focusten daarbij op eigenschappen van de melodie, eigenschappen van de harmonie (de akkoorden, en hoe de melodie zich daartoe verhoudt) en klankkleur of ‘timbre’.
Dimensies
We keken bijvoorbeeld wat voor intervallen, of sprongen tussen de noten van de melodie, er in het fragment voorkomen. Of is er sprake van een ruwe, dissonante textuur? In totaal geeft ons dat een kaart met 10 à 15 dimensies. Een erg ingewikkelde kaart dus, waarin elk muziekfragment wordt weergegeven door een punt met meer dan 10 coördinaten, terwijl de meeste kaarten die jij en ik dagelijks gebruiken er natuurlijk maar 2 hebben (of 3 of 4, zoals hieronder).
Typisch
Toch verrijken we onze data eerst nog verder. We willen namelijk vaak niet per se weten hoeveel van een bepaald soort intervallen er voorkomt, of hoe luid een passage precies is, maar hoe die cijfers zich verhouden tot een grotere context. Zijn er misschien abnormaal veel grote intervallen in een fragment, of is er juist een erg typische akkoordencombinatie? We willen dus weten hoe typisch of atypisch de melodie, harmonie en klankkleur zijn van een fragment X.
Maar hoe zie je dat op een kaart?
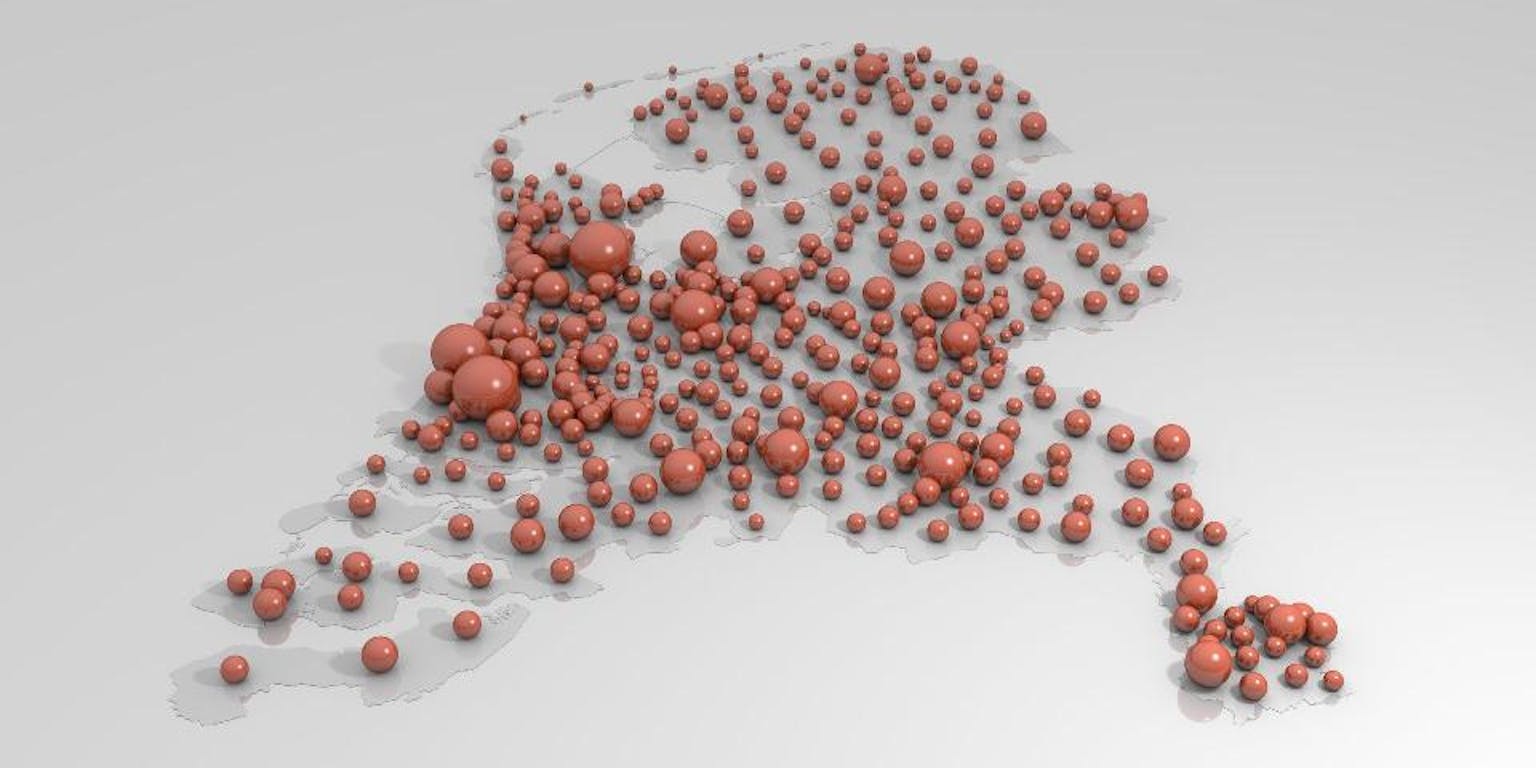
Je zou kunnen kijken hoeveel andere fragmenten er dichtbij je fragment X op je 10-dimensionale kaart liggen. Of kijken wat de gemiddelde afstand van X naar de dichtstbijzijnde andere fragmenten is. Of de ‘bevolkingsdichtheid’ in elk vakje van je kaart berekenen (zie de afbeelding hieronder). Dat soort berekeningen vallen onder ‘density estimation’, en hebben we toegepast op onze muzikale data.

Bevolkingsdichtheid in Nederland.
Terglobo — http://terglobo.nl/media.htmlGroeperen
Door de dataset met deze informatie te verrijken hebben we nu helaas nog meer dimensies aan ons been, wel drie keer zoveel. Gelukkig kunnen we er soms een paar groeperen, wanneer bijvoorbeeld twee van je dimensies bijna hetzelfde meten (luidheid en ‘energie’ bijvoorbeeld) of 2 dimensies steeds samen blijken voor te komen (zoals een atypische melodie en een atypische harmonie). Het groeperen van dimensies is precies wat je doet met Principal Component Analysis, een veelgebruikte statistische procedure.
Dat geeft ons in totaal 12 dimensies die we met de reactietijden uit Hooked! kunnen gaan vergelijken.
De resultaten daarvan… in de volgende blog!
'%20fill='%23000'%3e%3cpath%20d='M1.28%2022.5c-.505%200-.826-.018-.862-.018a.44.44%200%2001-.238-.792l2.425-1.778A8.266%208.266%200%2001.326%2014.22c0-4.559%203.71-8.268%208.268-8.268a8.269%208.269%200%20018.087%206.556c.119.559.176%201.135.176%201.716%200%204.554-3.705%208.263-8.263%208.263-.907%200-1.804-.15-2.667-.44-1.782.392-3.608.458-4.646.458V22.5zM8.595%206.83c-4.075%200-7.388%203.313-7.388%207.388%200%202.055.867%204.03%202.376%205.416.097.088.15.216.14.348a.448.448%200%2001-.18.33L1.774%2021.61c1.06-.022%202.609-.119%204.083-.458a.468.468%200%2001.246.013%207.414%207.414%200%20002.49.432c4.07%200%207.384-3.314%207.384-7.384a7.385%207.385%200%2000-6.41-7.322%207.849%207.849%200%2000-.973-.06z'/%3e%3cpath%20d='M20.944%2013.102c-.775%200-2.139-.049-3.48-.34-.37.124-.758.216-1.154.27a.44.44%200%2001-.492-.344%207.395%207.395%200%2000-6.253-5.795.44.44%200%2001-.383-.462A6.287%206.287%200%200115.462.5c3.334%200%206.296%202.825%206.296%206.296%200%201.571-.594%203.09-1.65%204.242l1.711%201.254a.439.439%200%2001-.238.792c-.03%200-.263.013-.637.013v.005zm-3.507-1.237c.03%200%20.066%200%20.097.009.941.216%201.918.3%202.675.33l-1.034-.761a.448.448%200%2001-.18-.33.431.431%200%2001.14-.348%205.412%205.412%200%20001.743-3.969A5.421%205.421%200%200015.46%201.38a5.407%205.407%200%2000-5.363%204.708%208.275%208.275%200%20016.48%206.002c.243-.053.48-.12.71-.198a.428.428%200%2001.149-.027z'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='prefix__clip0_1886_150885'%3e%3cpath%20fill='%23fff'%20transform='translate(0%20.5)'%20d='M0%200h22v22H0z'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e) Reageer
Reageer