
Voor een van mijn onderzoeken haalde ik informatie van websites door te scrapen. In deze blog leg ik uit wat webscrapen is, hoe je dit zelf doet en waar je op moet letten als je gaat webscrapen. Zo kan jij ook zelf een hoop informatie van het internet halen en onderzoeken.
Stel, je vraagt je af of films over virusuitbraken in de loop der tijd zijn veranderd. Zijn ze bijvoorbeeld enger of duren ze langer tegenwoordig? En worden de nieuwste pareltjes beter beoordeeld dan oude kaskrakers? Wikipedia heeft een pagina met films over virusuitbraken, maar het is lastig zo trends te zien – áls die er zijn. Om verbanden te onderzoeken kun je beter alle informatie in één overzichtelijke dataset stoppen. De informatie voor deze dataset verzamel je door te scrapen.
Wat is webscrapen?
Webscrapen is in feite het opslaan van informatie van websites op je eigen computer. Meestal wordt hiermee het geautomatiseerd ophalen van informatie bedoeld. Je kunt dit vergelijken met het maken van screenshots van een website. Websites bestaan meestal uit verschillende webpagina’s. Als je de website, of delen daarvan, offline wil opslaan dan kun je van iedere webpagina een screenshot maken. Voor een paar pagina’s is dit geen probleem. Voor heel veel pagina’s kost dit al snel heel veel tijd en vrij veel opslagruimte op je computer. Het is dan handiger het te automatiseren (lees: de computer al het werk laten doen). Om dit slim aan te pakken, duik je in de broncode van de website.
Onder de motorkap
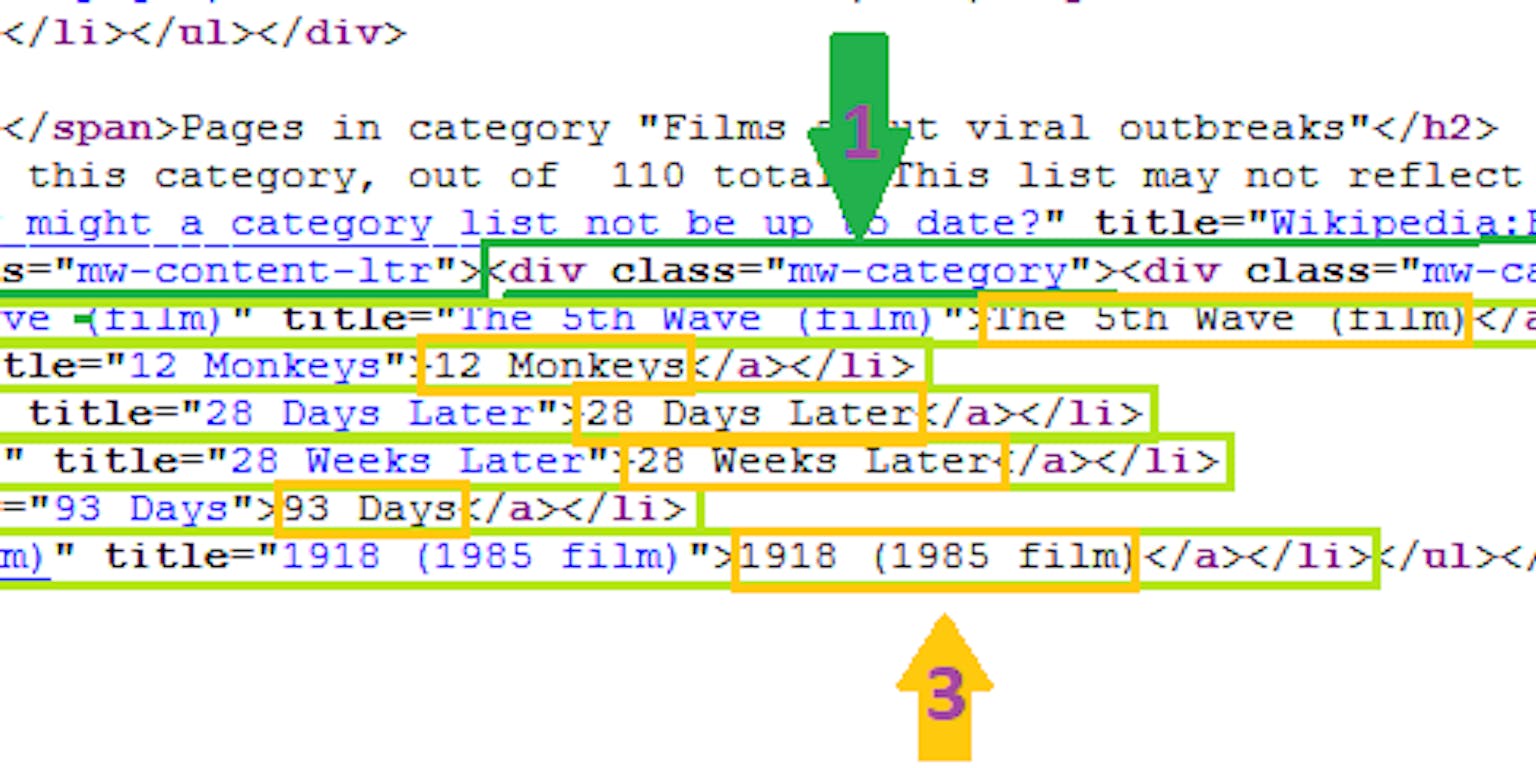
Alles wat je ziet op websites is code. De broncode van een webpagina is in feite de blauwdruk van die pagina. Die code zie je gelukkig niet direct – dat zou een rommeltje worden – maar tover je wel makkelijk tevoorschijn. Bij verschillende browsers werkt dit op verschillende manieren. Ik bespreek hier alleen Firefox en begin vanuit de Wikipedia pagina Category Films about viral outbreaks. Druk je op Ctrl + u (voor Mac gebruikers Cmd + u), dan verschijnt de broncode in een nieuw tabblad. Deze code gaan we scrapen.

De broncode van de Wikipediapagina die we gaan scrapen. Let op de HTML-tags < li >. Dit patroon gebruiken we straks om de scraper te verfijnen.
WikipediaGoed om te weten voor het scrapen (en parsen, wat ik straks uitleg) is dat de broncode gestructureerd is met tags. Deze tags zijn onderdeel van de taal HTML waarin de code geschreven is. Tags herken je aan de puntige haakjes. Voorbeelden zijn < div > en < li >. Voor nu volstaat om te weten dat code na een tag steeds wordt afgesloten met de corresponderende “afsluittag”, zoals < /div > en < /li >.
Hoe scrape je een pagina?
Om een webpagina te scrapen heb je een scraper nodig. Een scraper is het programmaatje dat de broncode van een webpagina ophaalt en op je computer opslaat. Op internet zijn goede tutorials te vinden over hoe je zelf een scraper maakt, bijvoorbeeld in Python of in R. Hieronder zie je een voorbeeld van een hele simpele scraper die ik iets verfijnd heb.

Voorbeeld van een simpele scraper om filmtitels van een Wikipedia pagina te halen. Het commentaar na “#” geeft aan wat er gebeurt.
WikipediaDeze scraper haalt niet alleen de broncode op, maar zoekt in de broncode ook naar de filmtitels die we vervolgens apart opslaan. Om deze specifieke informatie uit de broncode te halen, moet je weten waar in de broncode die informatie staat. Hiervoor kunnen we Ctrl + f op de broncode doen en zoeken naar filmtitels óf met de rechtermuisknop op de tekst klikken en “Inspect Element (Q)” selecteren. Onderin het scherm zien we dan binnen welke HTML tags de filmtitels staan. Deze tags staan in de scraper.

Dit is een overzichtelijke manier om snel te zien waar in de broncode de filmtitels staan.
WikipediaJe ziet de titels steeds na < li > tags staan. Omdat het gaat om meerdere titels, zijn er meerdere < li > tags. Om zo efficiënt mogelijk te scrapen, willen we het codeblok waar al die titels in staan én waar geen andere < li > tags in staan. Je komt dan uit op de code na de < div > tag met class “mw-category”.
Als je de scraper aanstuurt om in de broncode te kijken, dan leest hij het eerste tot aan het laatste teken in de broncode. Om de filmtitels te pakken, specificeer je een trechtermodel:
1. Vind eerst de < div > tag met class “mw-category” en pak de code tussen deze tag en < /div >.
2. Vind alle < li > tags en pak steeds de code tussen deze tags en de < /li > tags.
3. Print de tekst tussen de < li > en < /li > tags die zichtbaar is op de webpagina.

De verschillende tags die de scraper afgaat. De scraper stopt automatisch met zoeken na een “afsluittag”
WikipediaWat kan je daar vervolgens mee?
Nu hebben we dus een lijst met titels van films over virusuitbraken, maar we wilden weten hoe dit soort films over de jaren zijn veranderd. Dan hebben we meer informatie nodig: in ieder geval een jaartal en, bijvoorbeeld, genres en review scores. Als we deze informatie overzichtelijk bij elkaar zetten in één databestand dan kunnen we die makkelijk analyseren.
In mijn eigen onderzoek naar informatie op illegale online markten maakte ik onderscheid tussen scrapen en parsen. Parsen is het extraheren van informatie uit de broncode. In mijn onderzoek wilde ik weten hoe verschillende advertentie-elementen (zoals prijs en feedback) gerelateerd waren aan verandering in de populariteit van een advertentie. Maakte, bijvoorbeeld, continue positieve feedback een advertentie populairder? Hiervoor scrapete ik gedurende een paar weken de volledige broncode van advertentiepagina’s. Achteraf parste ik deze offline. Enkele voordelen hiervan zijn dat de scraper sneller z’n werk doet en je de volledige broncode opslaat op je computer in plaats van delen daarvan. Als pagina’s niet allemaal hetzelfde zijn gestructureerd en je komt daar pas later achter omdat informatie in je dataset ontbreekt, dan kan je de parser achteraf nog makkelijk aanpassen.
Voor de dataset van virusfilms is het ook handiger scrapen en parsen te scheiden. De informatie scrape je eerst van de filmpagina’s. Omdat deze niet allemaal hetzelfde zijn gestructureerd, parse je de broncode achteraf. Op mijn Github pagina zie je een voorbeeld van een filmpagina scraper en een parser.
Mag dit allemaal zomaar?
Wanneer je websites scrapet, moet je op een aantal dingen letten om het zo netjes mogelijk te doen. Zo moet je jouw scraper niet te snel laten gaan. Snel informatie verzamelen zonder dat je zelf als een gek moet klikken is een groot voordeel van scrapen, maar als jij je scraper niet in toom houdt, dan stuurt je computer te snel verzoeken (om broncodes) naar de server van de website. Hierdoor kan de server overbelast raken. Dit spamgedrag kan er ook voor zorgen dat de website jouw IP adres in het vervolg blokkeert.
Een ander punt is dat je goed de voorwaarden van de website moet lezen. Vaak staat op de “robots.txt” pagina wat je niet mag scrapen. Als je NemoKennislink wilt scrapen, moet je dus eerst hier kijken. Daarnaast kunnen websites ook voorwaarden hebben gesteld op hun Voorwaardenpagina. Ik wilde bijvoorbeeld eerst IMDb scrapen en daar wat moois van laten zien, maar na het lezen van deze voorwaarden ging ik toch twijfelen of dat zomaar mocht.
Tot slot nog een tip: Scrape This Site is een aardige website om te oefenen met scrapen. Succes en happy scraping!
'%20fill='%23000'%3e%3cpath%20d='M1.28%2022.5c-.505%200-.826-.018-.862-.018a.44.44%200%2001-.238-.792l2.425-1.778A8.266%208.266%200%2001.326%2014.22c0-4.559%203.71-8.268%208.268-8.268a8.269%208.269%200%20018.087%206.556c.119.559.176%201.135.176%201.716%200%204.554-3.705%208.263-8.263%208.263-.907%200-1.804-.15-2.667-.44-1.782.392-3.608.458-4.646.458V22.5zM8.595%206.83c-4.075%200-7.388%203.313-7.388%207.388%200%202.055.867%204.03%202.376%205.416.097.088.15.216.14.348a.448.448%200%2001-.18.33L1.774%2021.61c1.06-.022%202.609-.119%204.083-.458a.468.468%200%2001.246.013%207.414%207.414%200%20002.49.432c4.07%200%207.384-3.314%207.384-7.384a7.385%207.385%200%2000-6.41-7.322%207.849%207.849%200%2000-.973-.06z'/%3e%3cpath%20d='M20.944%2013.102c-.775%200-2.139-.049-3.48-.34-.37.124-.758.216-1.154.27a.44.44%200%2001-.492-.344%207.395%207.395%200%2000-6.253-5.795.44.44%200%2001-.383-.462A6.287%206.287%200%200115.462.5c3.334%200%206.296%202.825%206.296%206.296%200%201.571-.594%203.09-1.65%204.242l1.711%201.254a.439.439%200%2001-.238.792c-.03%200-.263.013-.637.013v.005zm-3.507-1.237c.03%200%20.066%200%20.097.009.941.216%201.918.3%202.675.33l-1.034-.761a.448.448%200%2001-.18-.33.431.431%200%2001.14-.348%205.412%205.412%200%20001.743-3.969A5.421%205.421%200%200015.46%201.38a5.407%205.407%200%2000-5.363%204.708%208.275%208.275%200%20016.48%206.002c.243-.053.48-.12.71-.198a.428.428%200%2001.149-.027z'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='prefix__clip0_1886_150885'%3e%3cpath%20fill='%23fff'%20transform='translate(0%20.5)'%20d='M0%200h22v22H0z'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e) Reageer
Reageer